数据结构类型
- 数据结构分类
- 数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成(说白了就是组织数据的方式)。
- 常用的数据结构有:数组,栈,链表,队列,树,图,堆,散列表等,如图所示:
- 每一种数据结构都有着独特的数据存储方式。
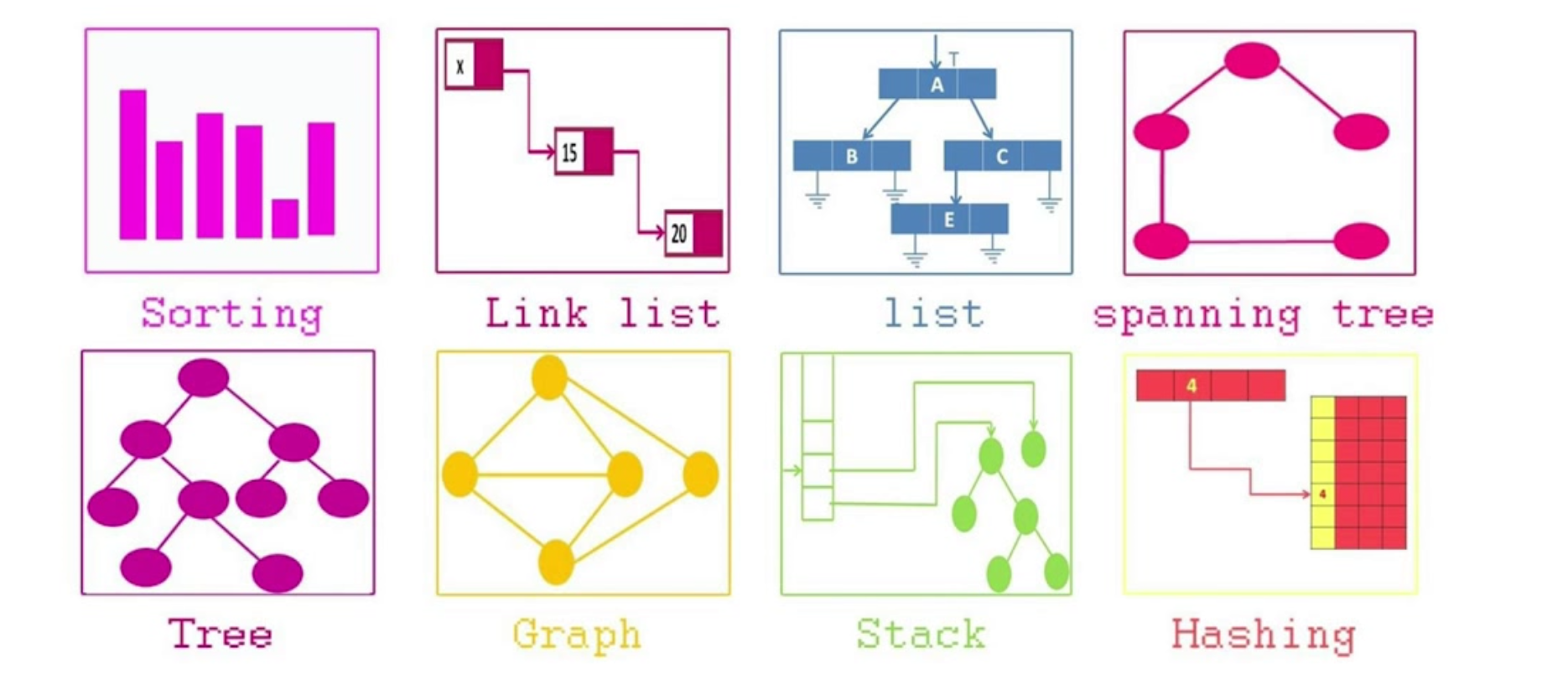
-
四大常用结构
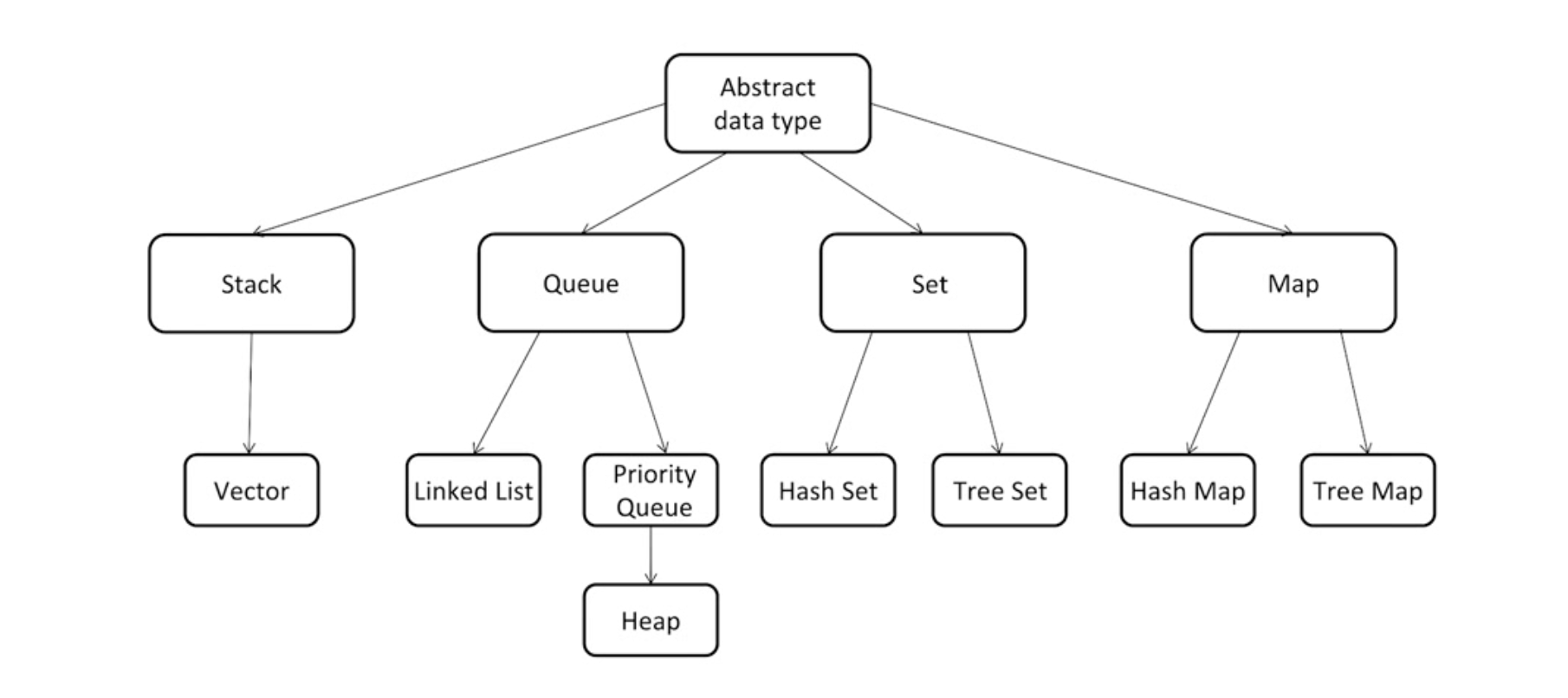
-
数据结构和算法类别

-
Big O notation (时间和空间复杂度)

示例如下:


O^n 变化图
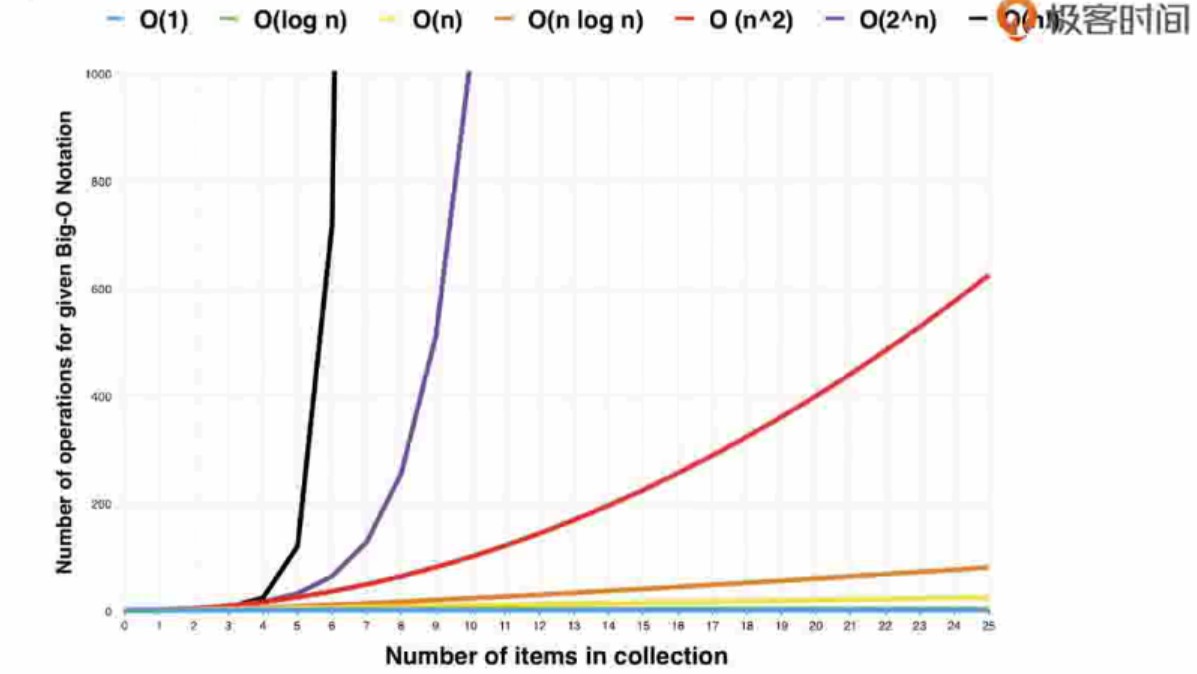
-
递归(recursion)
# 斐波纳契数组 是O(2^n) 时间复杂度 # Fibonacci array:1,1,2,3,5,8,13,21,34,... # F(n) = F(n-1) + F(n-2) def fib(n): if n==0 or n==1: return n return fib(n-1) + fib(n-2) -
常用几类递归算法的时间复杂度
- 二分查找:O(log n)
- 二叉树遍历:O(n)
- 排序和二维矩阵的查找:O(n)
- 排序和归并排序:O(n*log n)
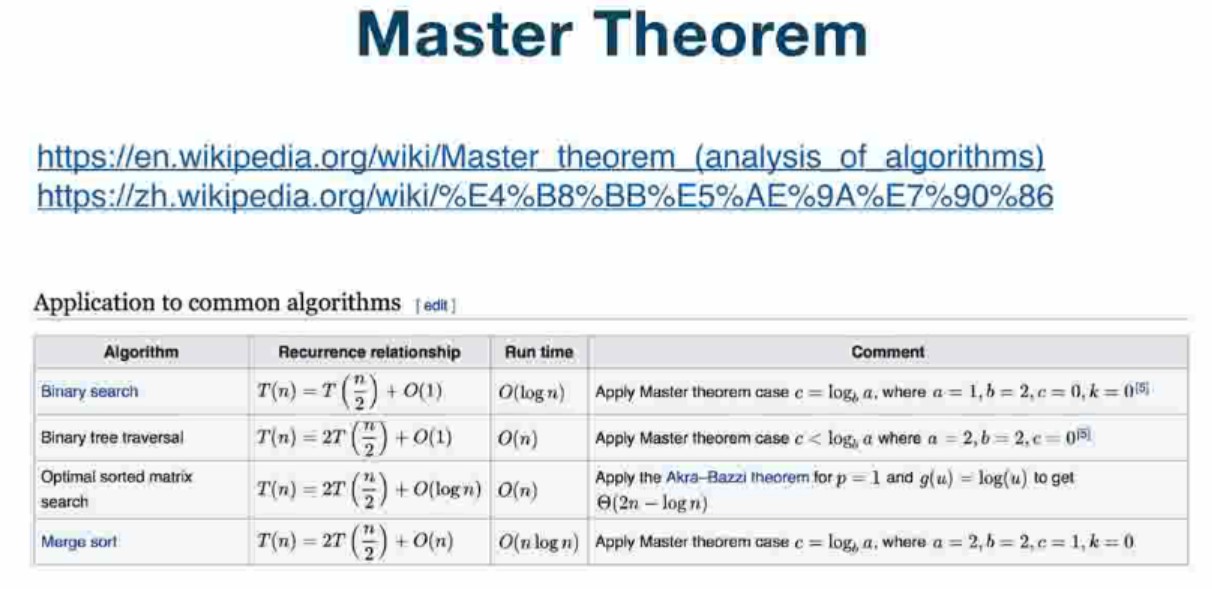
-
Array-内存中的连续存储空间
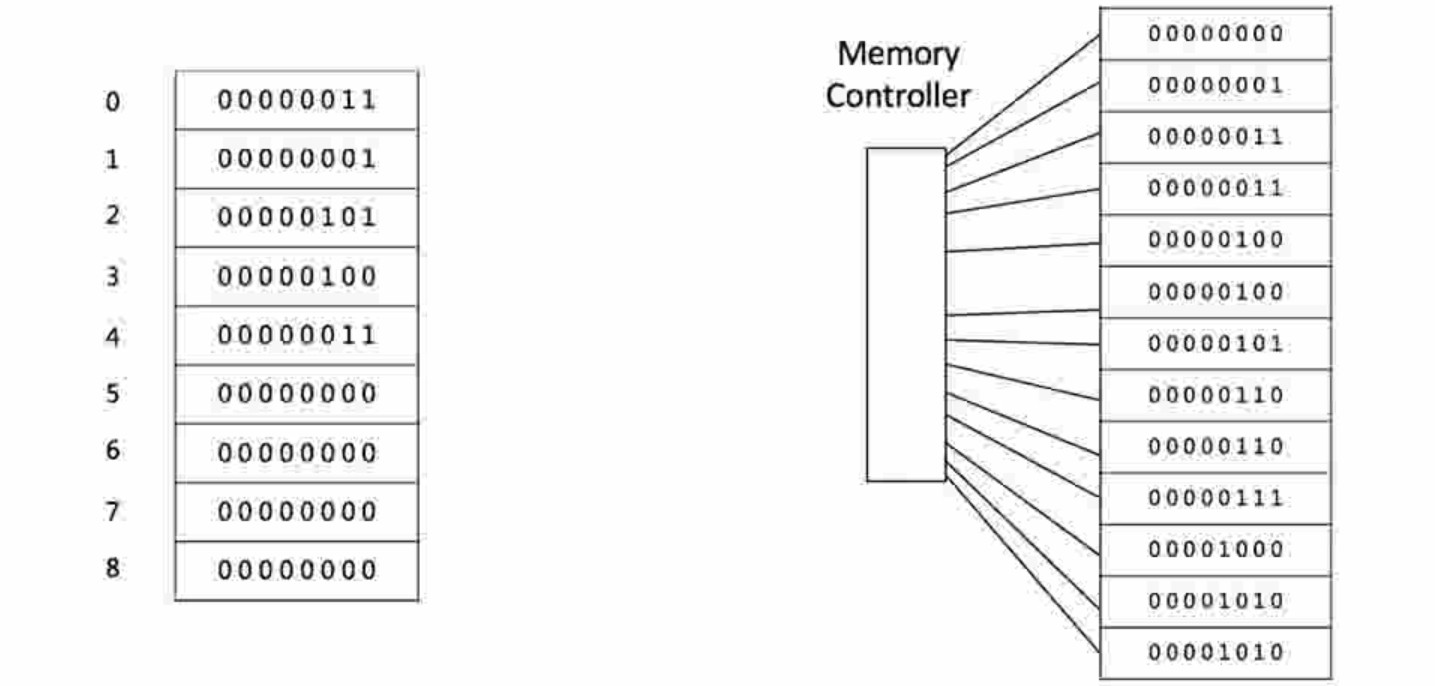
Array的查找的时间复杂度为o(1),插入和删除为o(n)复杂度,这也是数组作为存储在连续空间的数据的缺陷所在,为了改善插入和删除操作。因此后面产生了链表Linked List。
- 链表
-
Single Linked List (单链表)
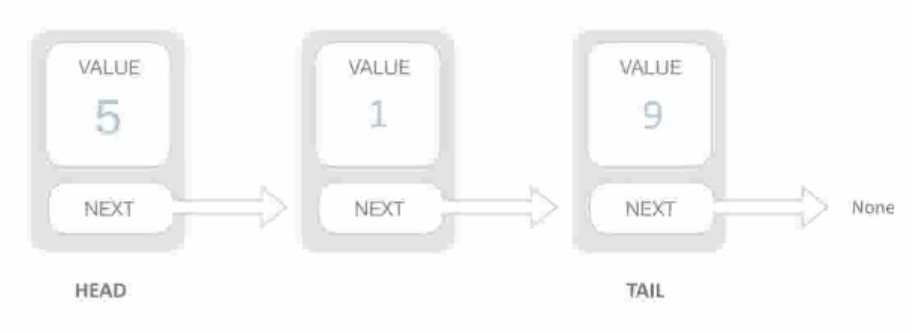
-
单链表的变形形式(增加了头尾指针)
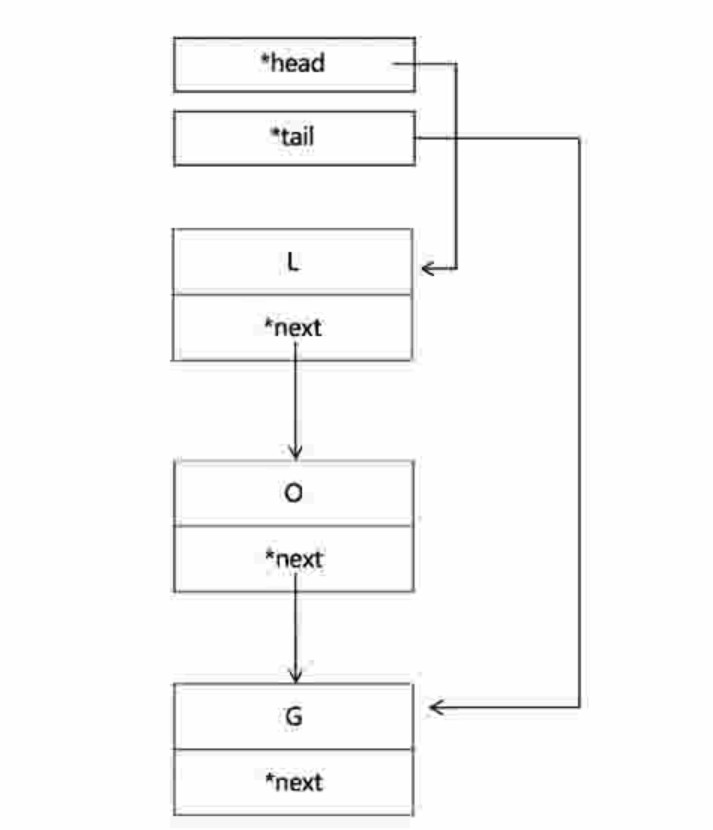
-
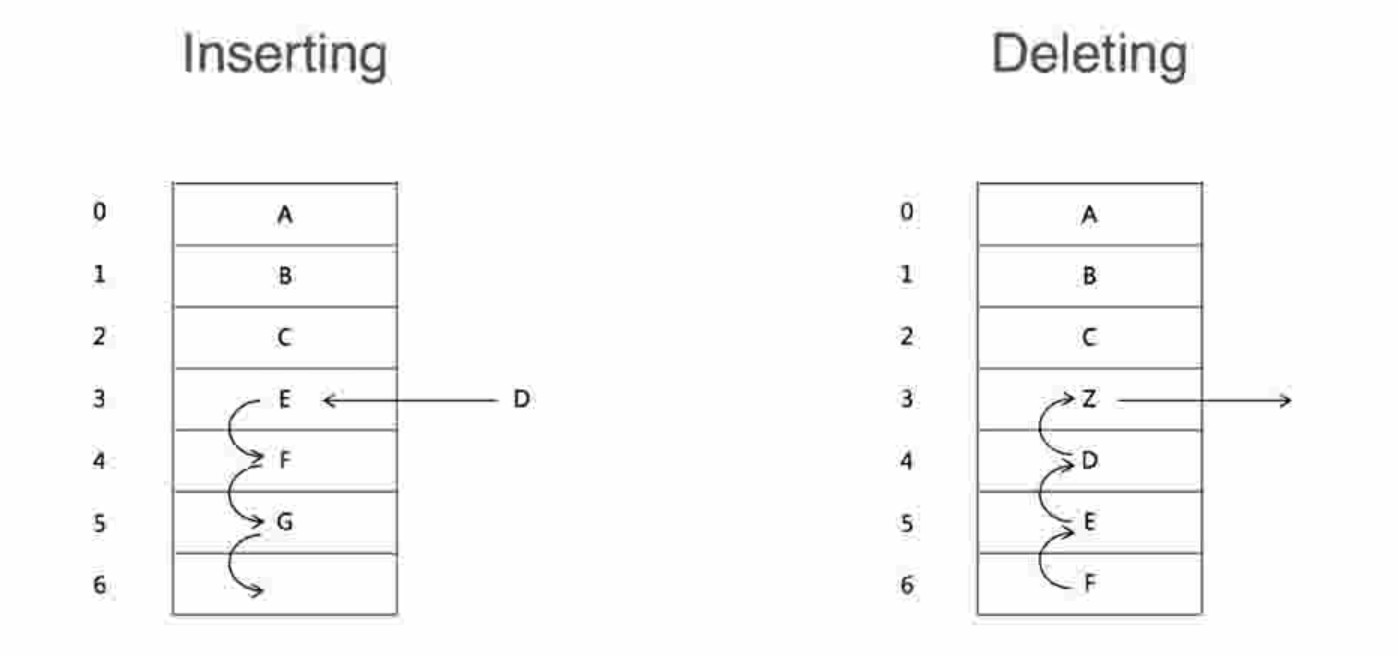
链表的插入和删除操作(时间复杂度为o(1))
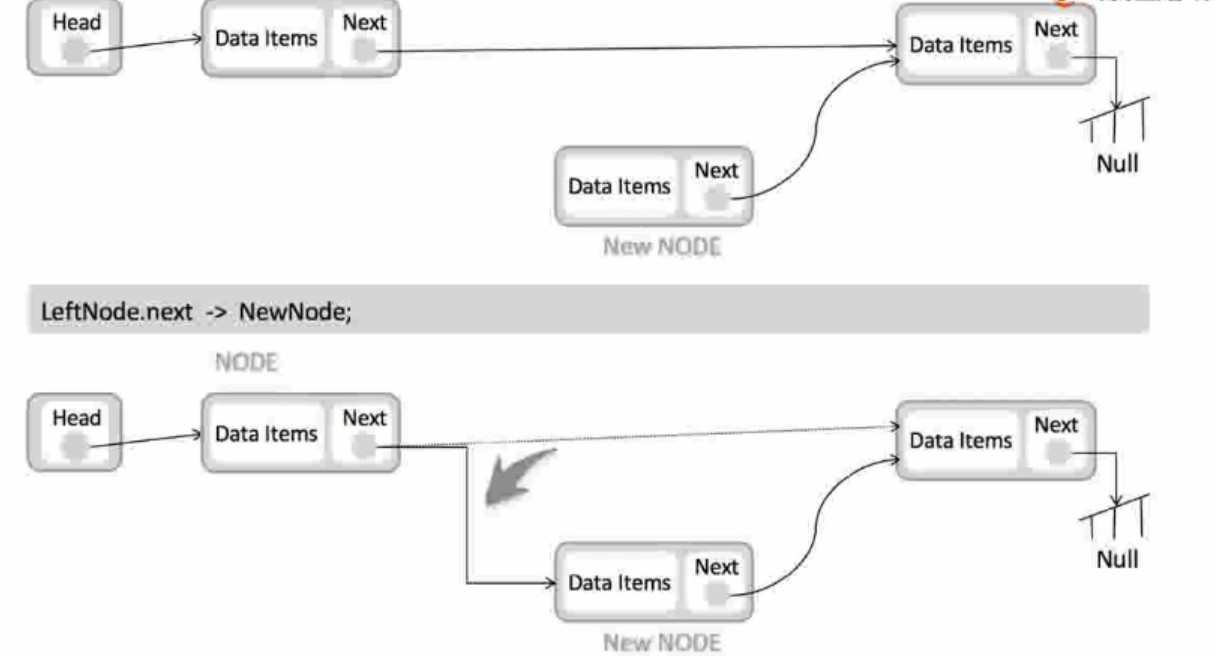
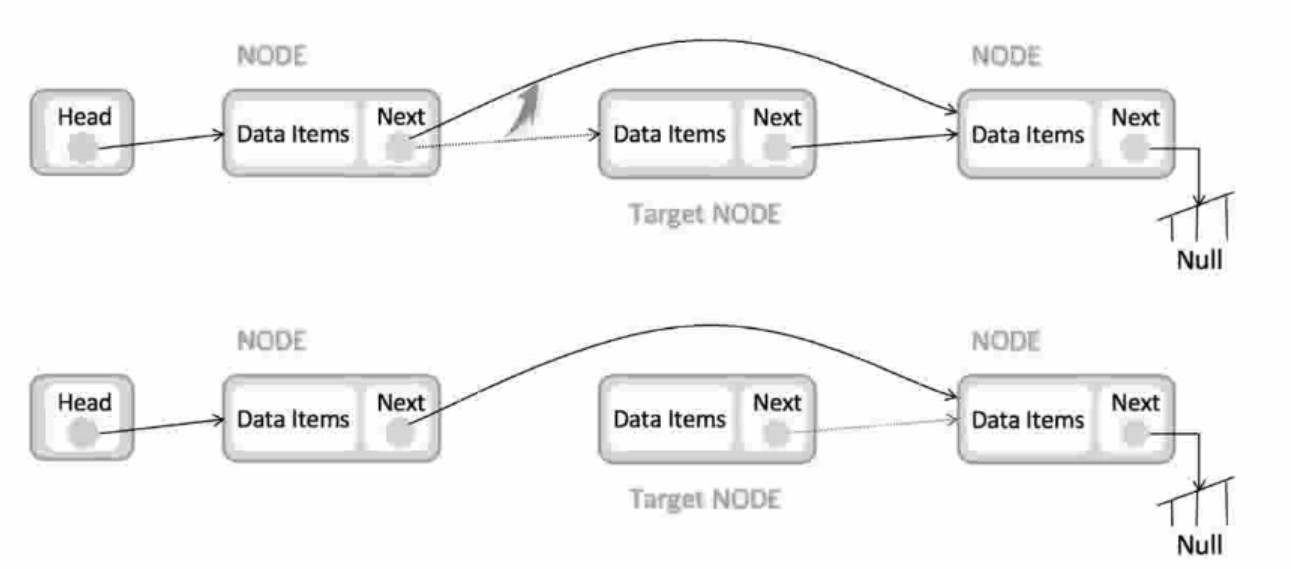
-
-
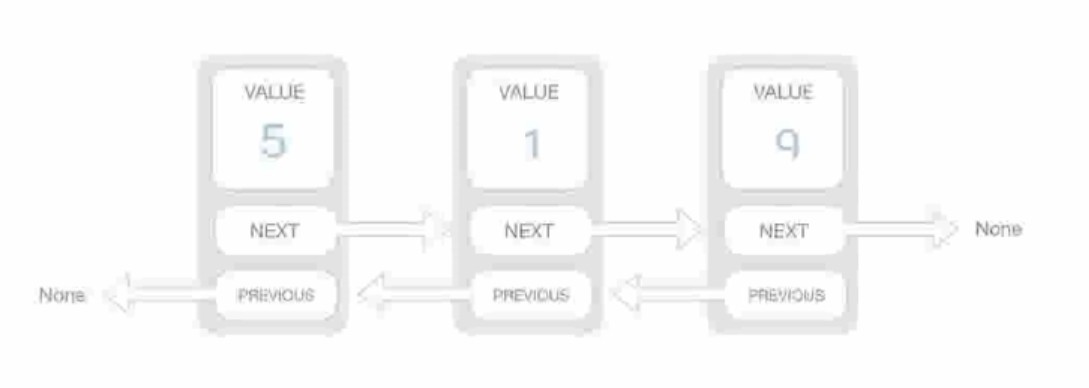
Doubly Linked List (双链表:既有前驱也有后继,查询更方便)
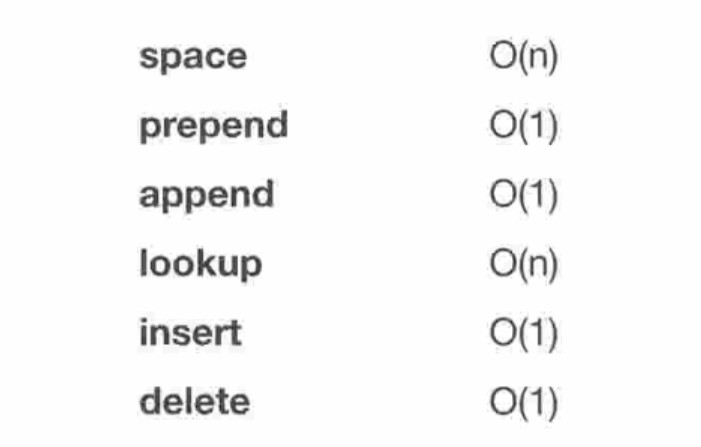
链表的时间复杂度总结:
-
-
堆栈和队列(Stack/Queue)
- Stack - First In Last Out (FILO)
- Array or Linked List(实现)
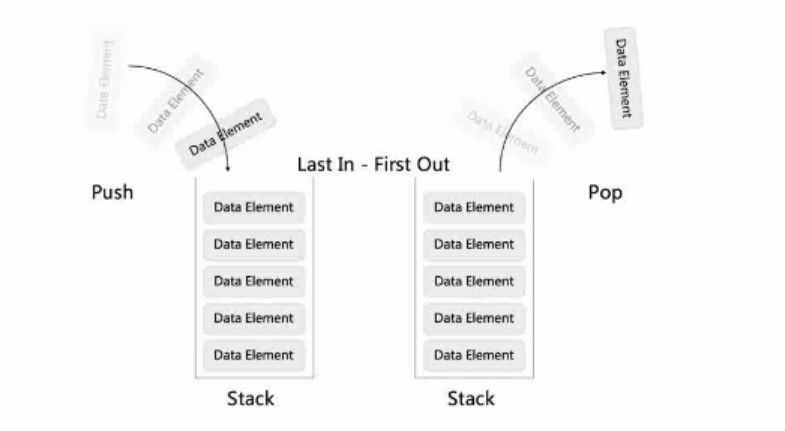
- Array or Linked List(实现)
- Queue - First In First Out (FIFO)
- Array or Doubly Linked List(实现)
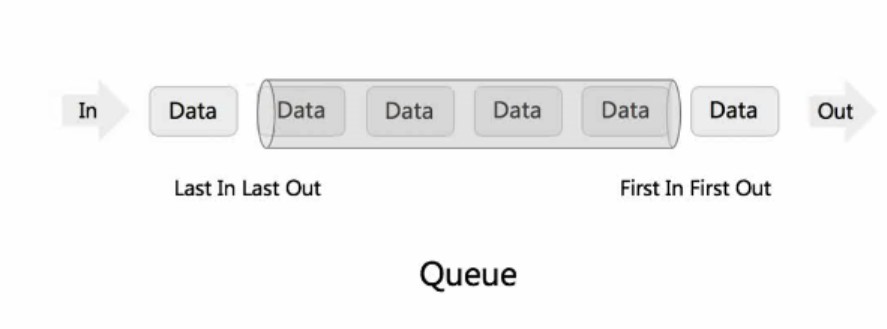
- Array or Doubly Linked List(实现)
- Stack - First In Last Out (FILO)
-
各种数据结构的时间复杂度
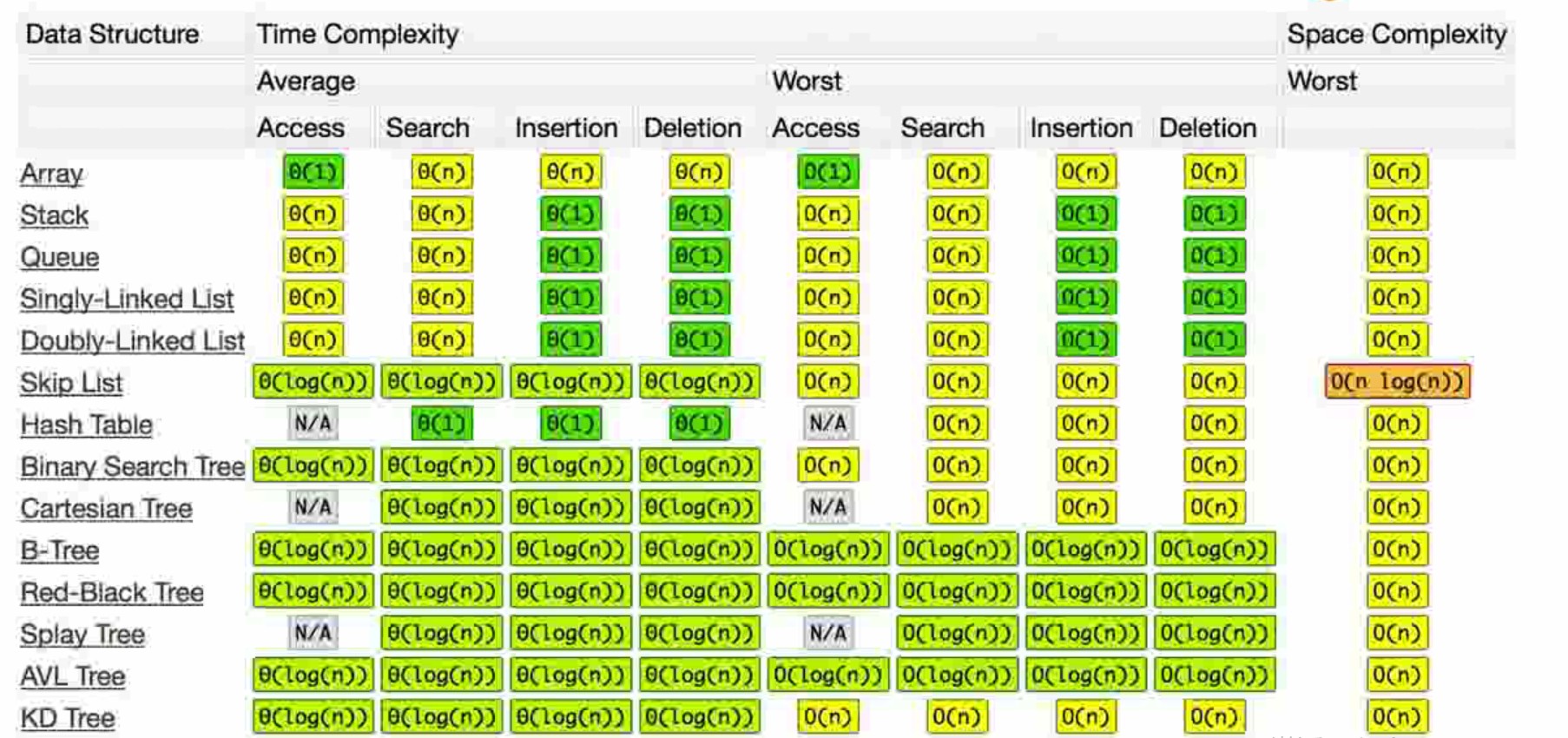
链接:http://www.bigocheatsheet.com/
-
-
优先队列(PriotityQueue)
- 正常入,按照优先级出
- 实现机制
-
Heap(堆)—Binary,Binomial,Fibonacca
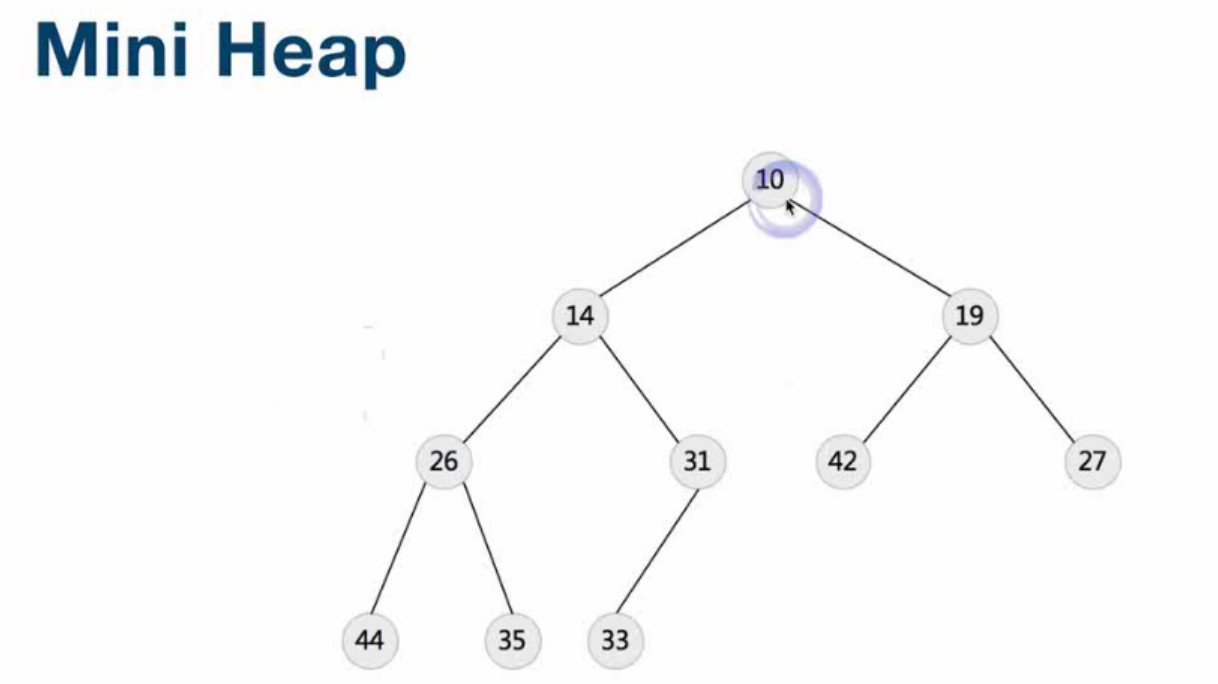
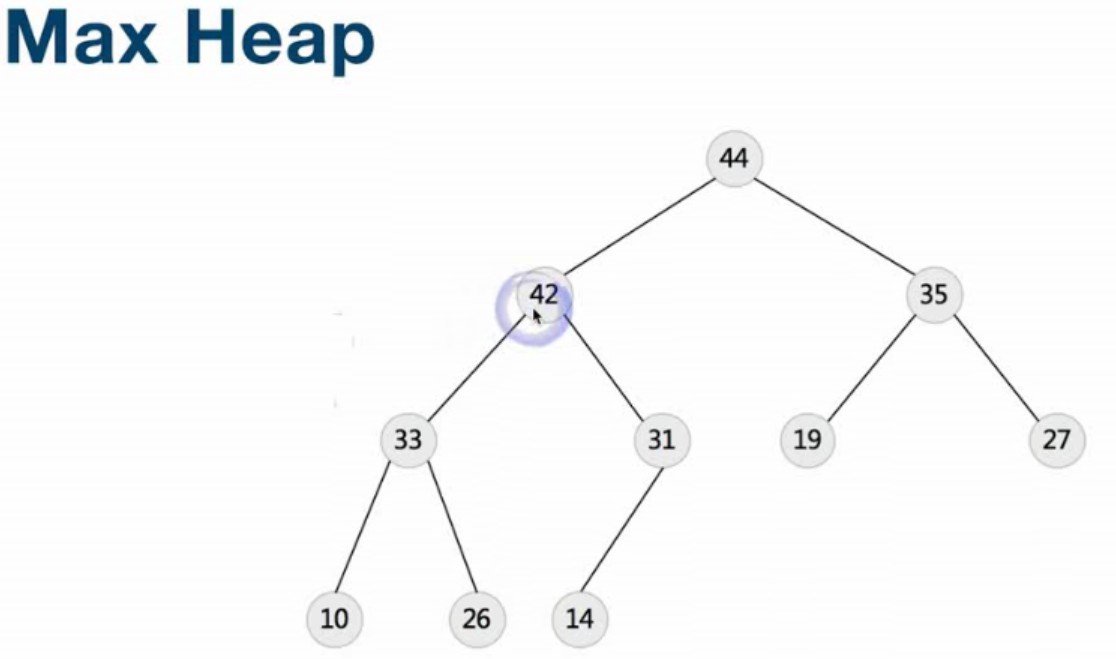
堆的介绍:https://en.wikipedia.org/wiki/Heap_(data_structure)
-
Binary S(earch Tree(二叉搜索树)
-
- 映射(Map) & 集合(Set)
-
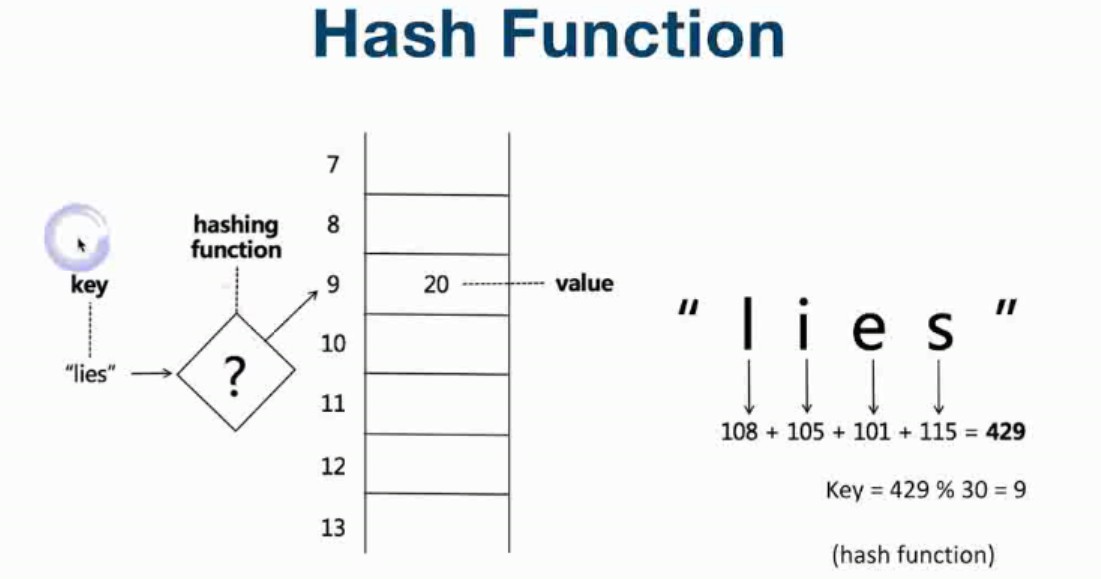
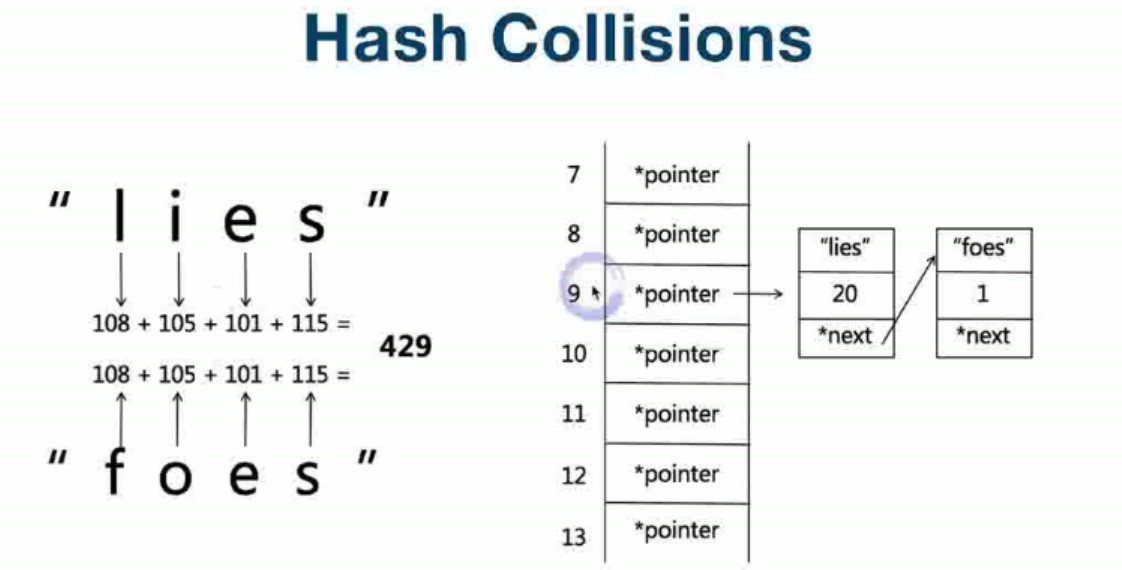
HashTable(哈希表) & HashFunction(哈希函数) & Hash Collisions(哈希碰撞)
如何解决hash碰撞问题:建立链表放置重复元素
-
List vs Map vs Set
list就是一个链,所有元素再同一个表里面。map映射是key和value的关系。set可以理解为不重复的list(使用hash表或者二叉树实现)

-
HashMap,HashSet,TreeMap,TreeSet(hashtable vs binary-search-tree)
-
- 树 & 二叉树 & 二叉搜索树
-
tree & Binary Tree & Binary Search Tree
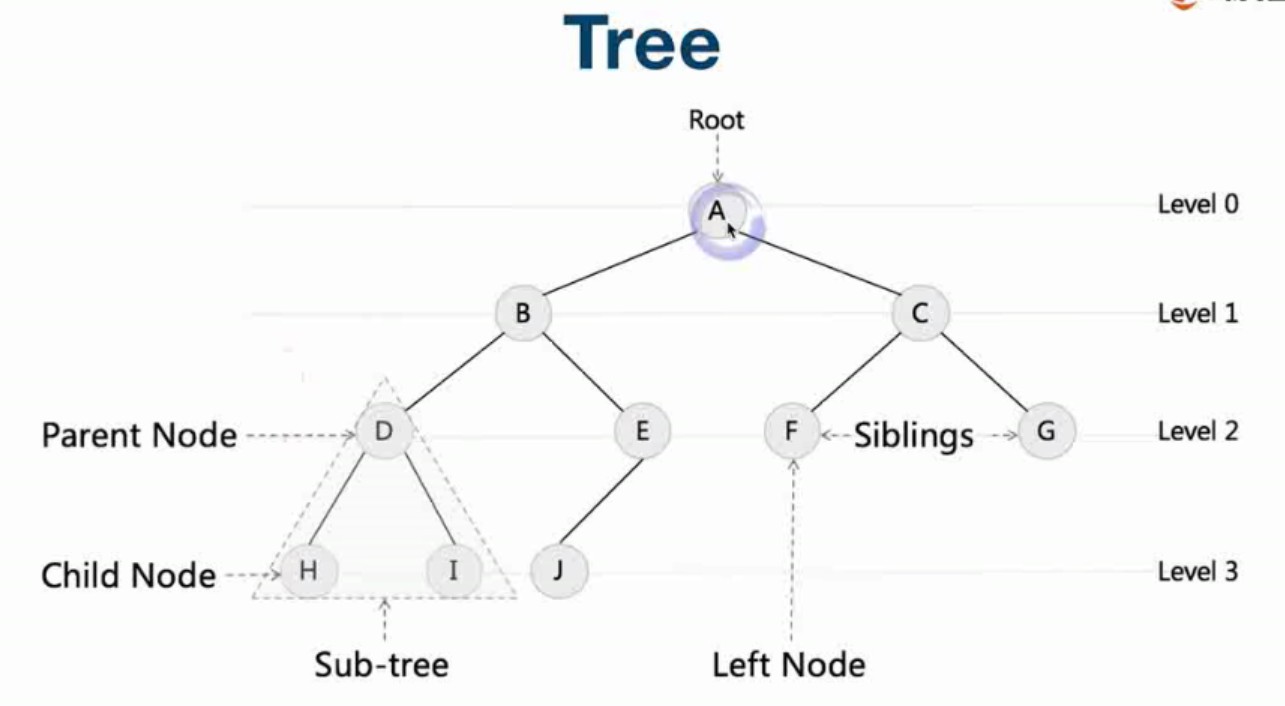
- 二叉树就是每个树都有两个子节点,如上图所示,为特殊常用的树结构
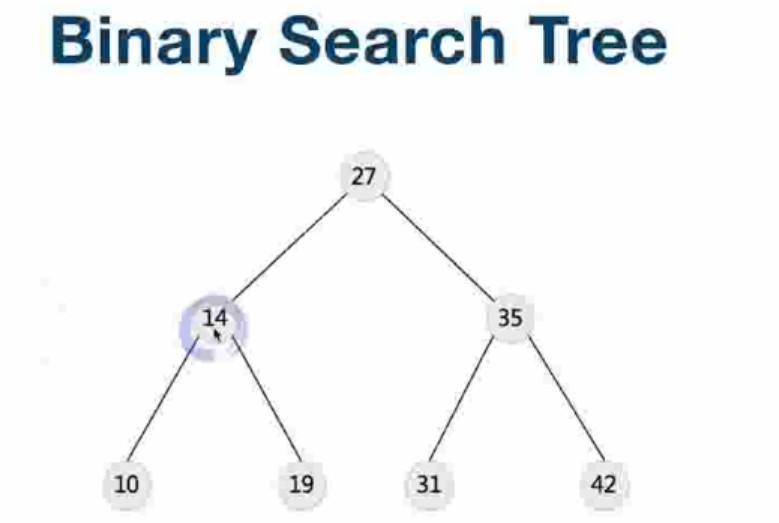
- 二叉搜索树(有序二叉树,排序二叉树):是指一棵空树或者具有以下性质的二叉树(红黑树也是二叉搜索树):
- 左子树上所有的节点的值均小于它的根节点的值
- 右子树上所有的节点的值均大于它的根节点的值
- Recursively,左/右子树也分别为二叉查找树
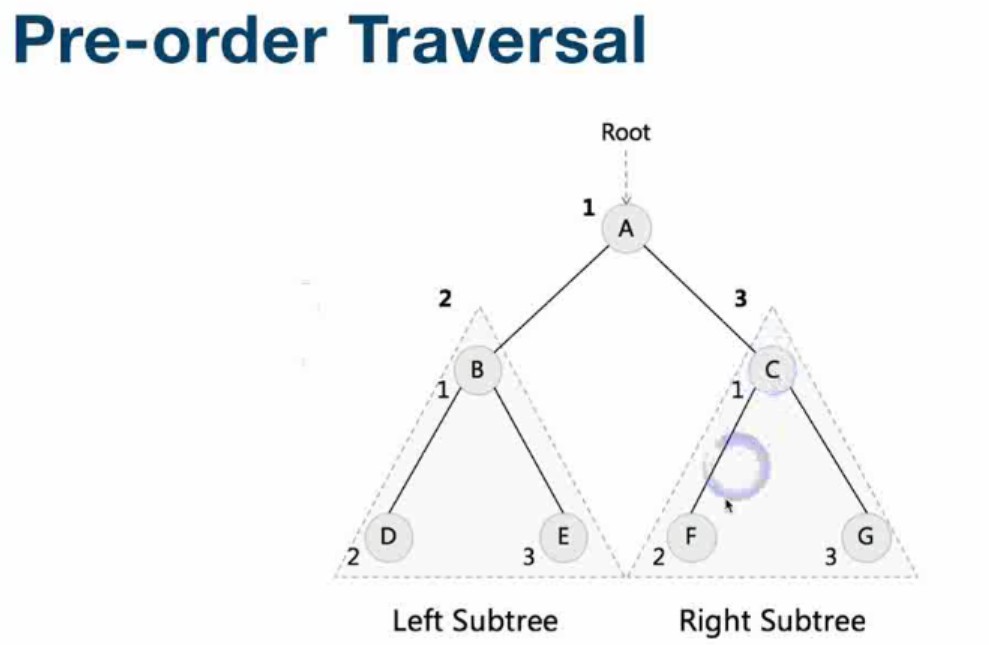
- 二叉树的遍历(pre-order/in-order/post-order: 前中后遍历)

- 前序遍历(root-左-右)
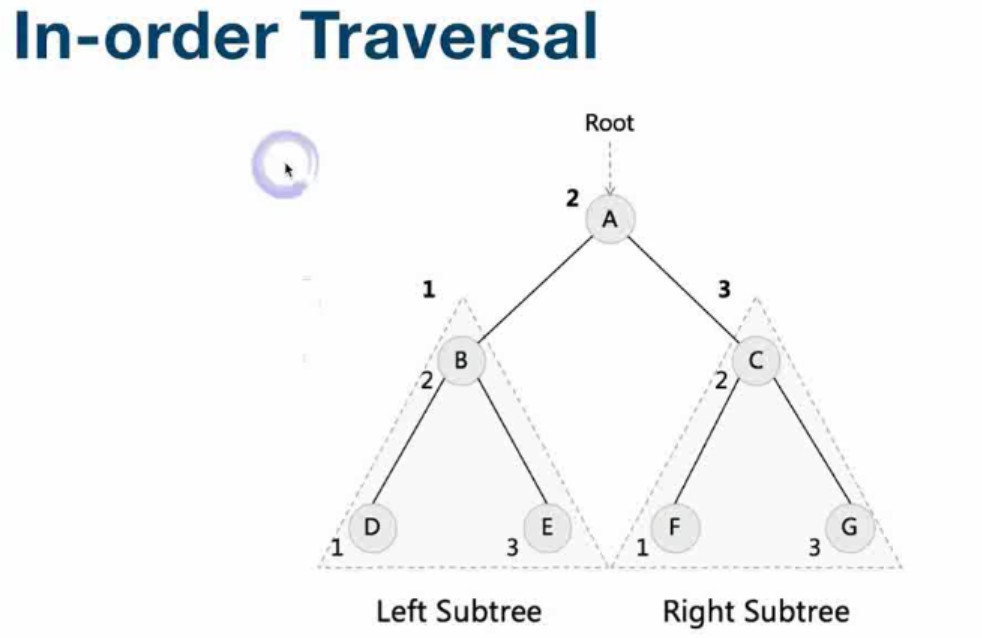
- 中序遍历(左-root-右)
- 后序遍历(左-右-root)
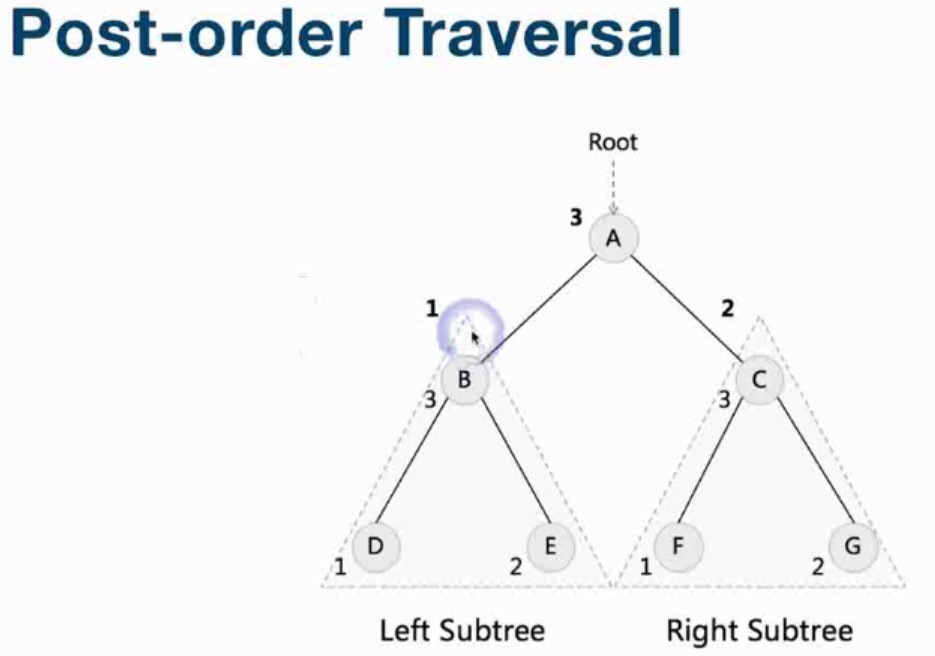
- 示例
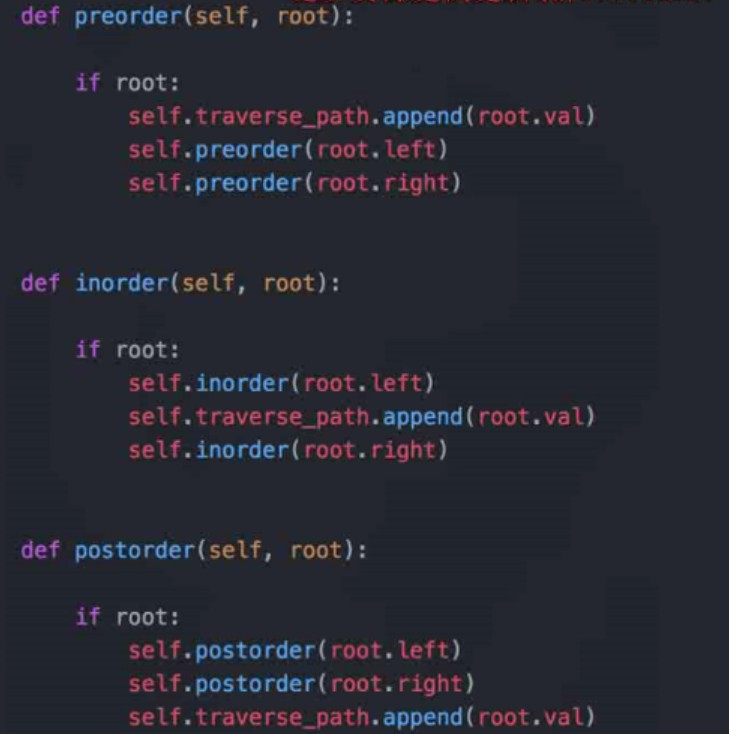
- 前序遍历(root-左-右)
-
Graph
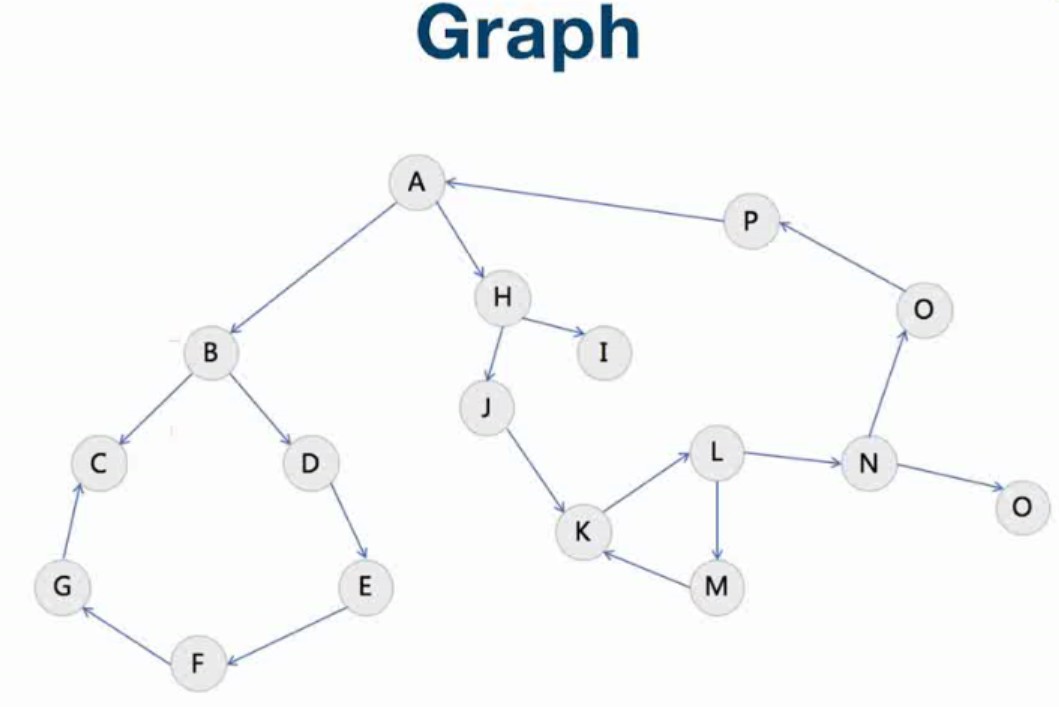
可以简单这样理解:Linked List就是特殊化的tree(单个next指针), Tree就是特殊化的Graph
-
- 递归(Recursion)、分治(Divide & Conquer)
- 递归:通过函数体来进行的循环
# n*(n-1)*(n-2)...*1 def Factorial(n): if n <= 1: return 1 return n * Factorial(n-1)def recursion(level, param1, param2,...): # recursion terminal if level > MAX_LEVEL: print result return # process logic in recursion level process_data(level,data...) # drop down self.recursion(level+1, p1,...) # reverse the current level state if needed reverse_state(level)# Fibonacci array:1,1,2,3,5,8,13,21,34... def fib(n): if n == 0 or n == 1: return n return fib(n-1)+fib(n-2) - 分治
-
将大问题分成多个小问题解决,和递归不同的是没有中间问题,可以参照分布式的思想。
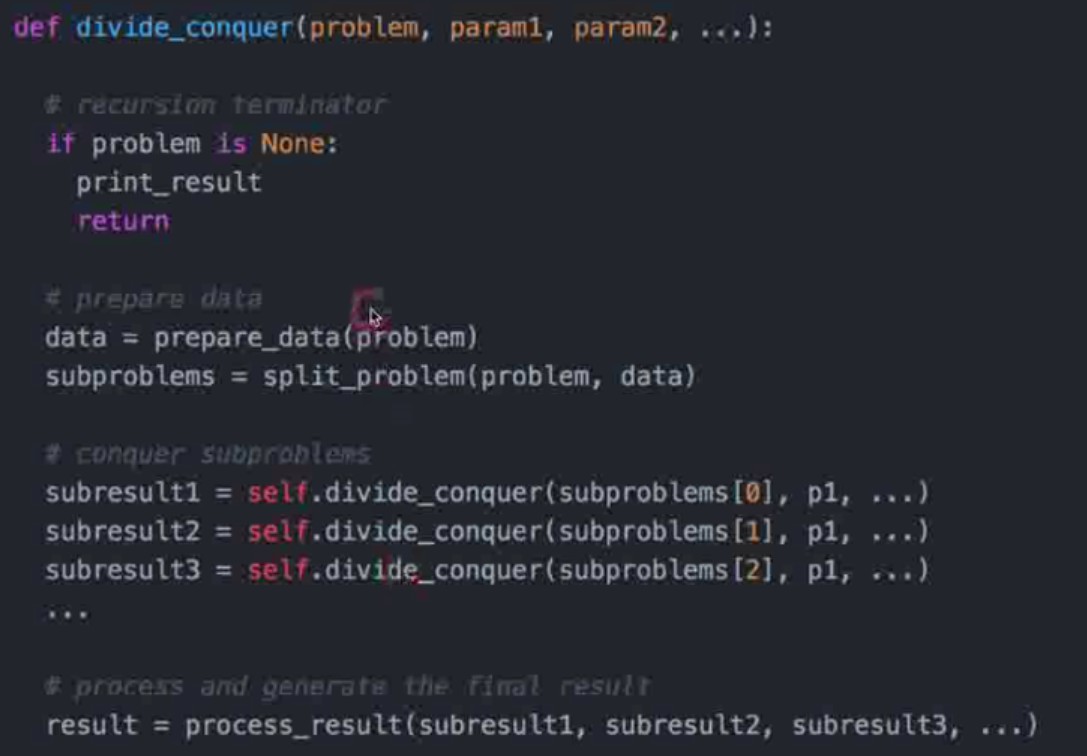
# 分治递归方法 def myPow(self,x,n): if not n: return 1 if n < 0: return 1 / self.myPow(x,-n) if n % 2: return x * self.myPow(x,n-1) return self.myPow(x*x,n/2 )# 非递归方法 def myPow(self, x, n): if n < 0: x = 1/x n = -n pow = 1 while n: if n & 1: pow *= x x *= x n >>= 1 return pow
-
- 递归:通过函数体来进行的循环
- 贪心算法(Greedy)
在对问题求解时,总是做出在当前看来最好的选择(部分情况下可以得到最优结果)
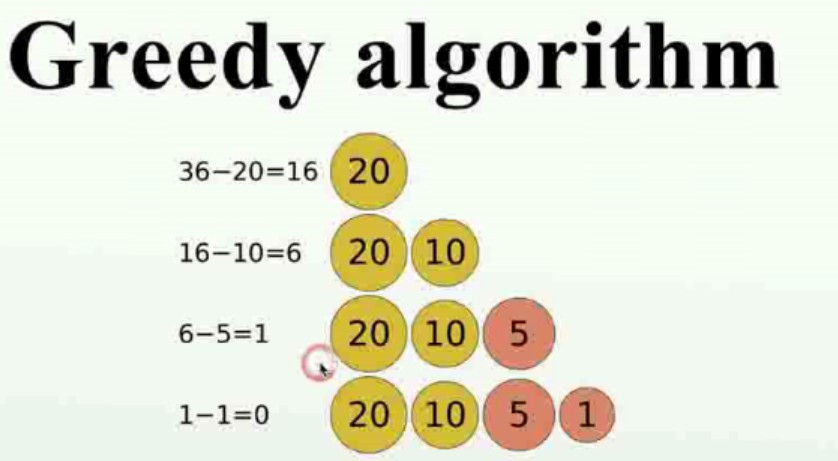

-
广度优先搜索(Breadth-First-Fearch)—非递归方法
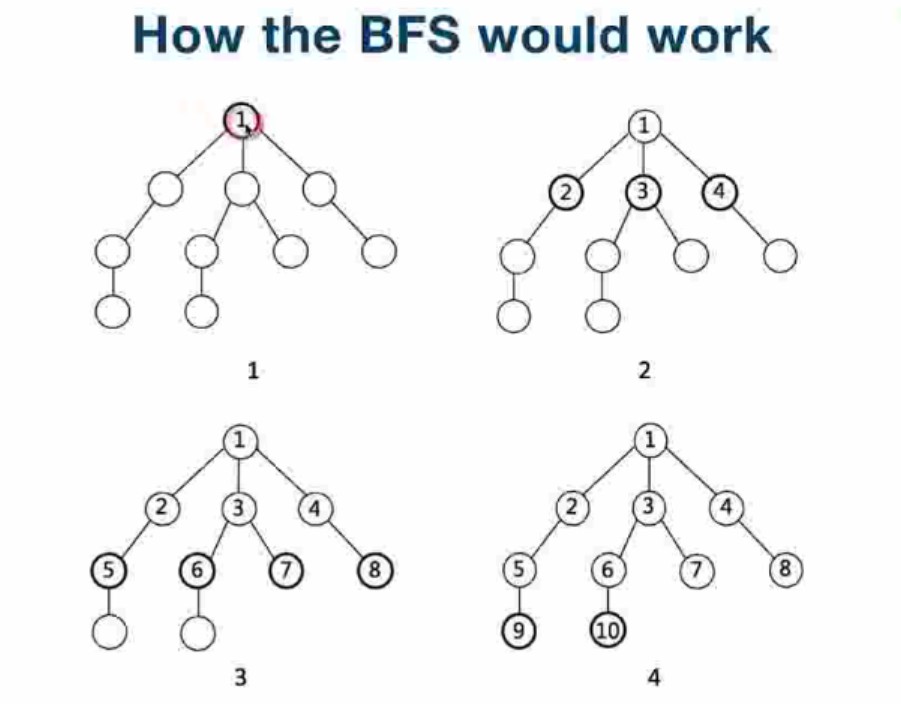
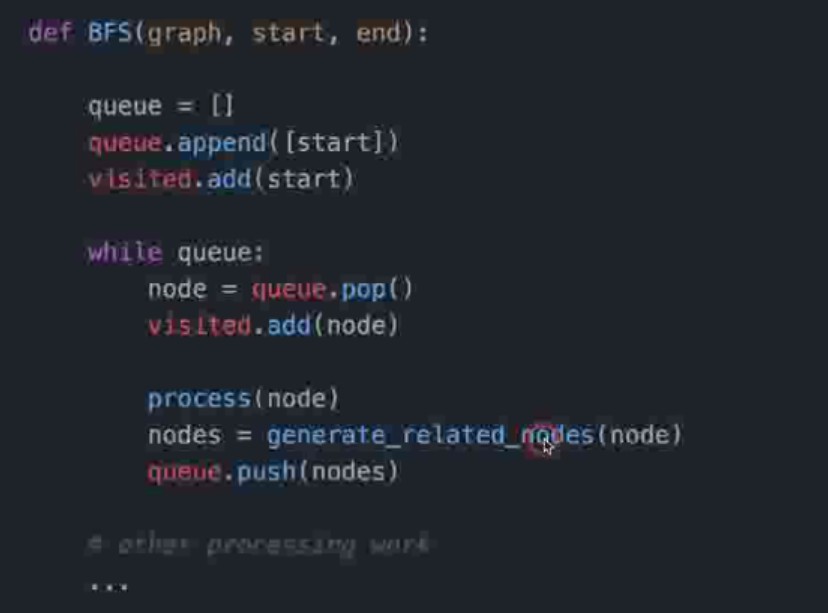
-
深度优先搜索(Depth-First-Fearch)—推荐用递归方法
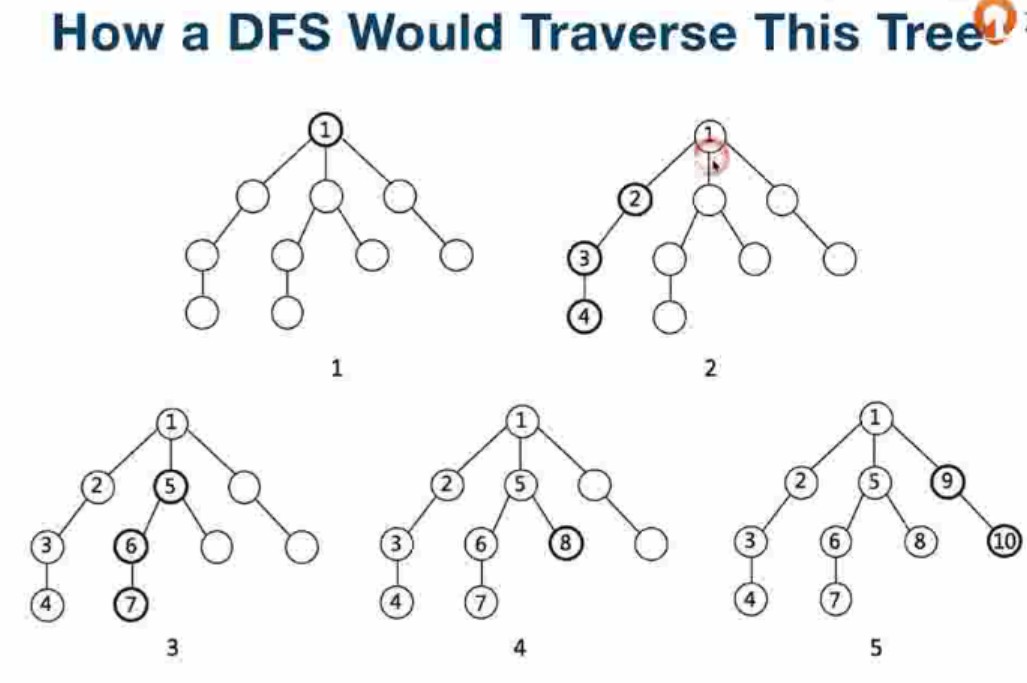
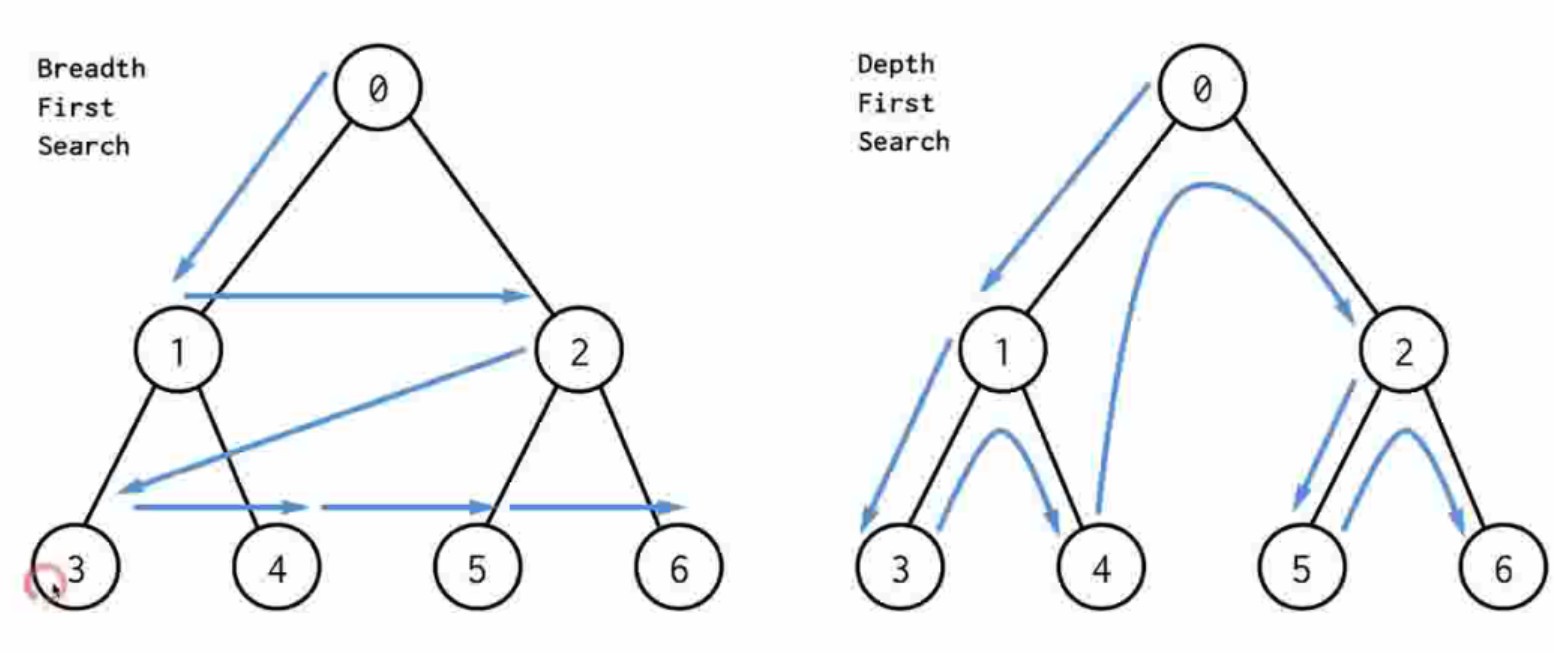
- 对比DFS和BFS
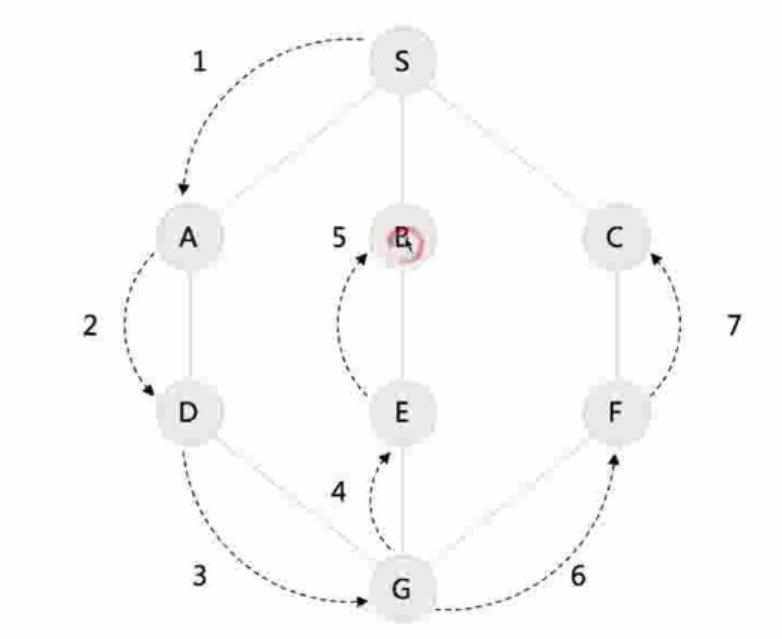
- 示例

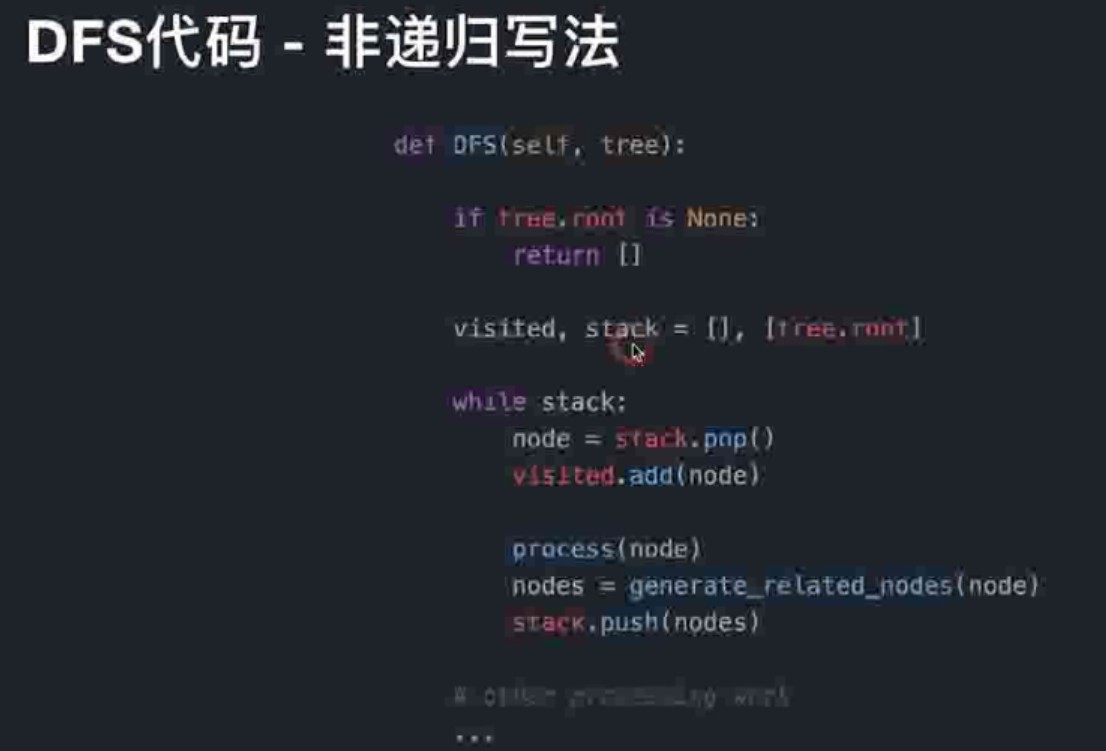
- 剪枝
- 是在搜索中经常使用的优化策略,修剪掉较差的枝叶,保留条件较好的枝叶,以便后面的搜索(适用层数不太高的阶层)
- 二分查找(Binary Search)
二分查找适用于满足下面条件的例子,数组很适合二分查找,链表不适合。
- Sorted(单调递增或者递减)
- Bounded(存在上下边界)
- Accessible by index(能够索引访问)
比如常用在寻找递增数列的中间数或者求某个数的平方根等等
- 字典树
适用于模糊搜索的场景,比如Google,Baidu
- Trie树的数据结构
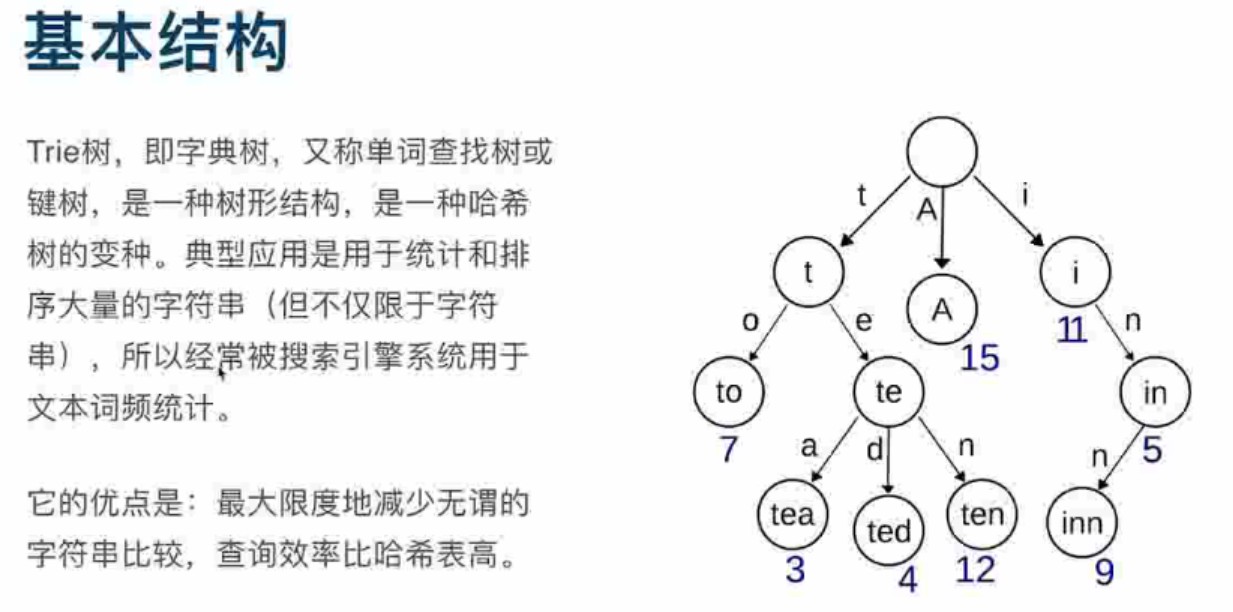
- Trie树的核心思想
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的花销以达到提高效率的目的。
- Trie树的数据结构
- 位运算
位运算就是直接对内存中的二进制位进行操作,由于位运算直接对内存数据进行操作,不需要转化成10进制,因此处理速度快,如下是运算规则。

-
异或的应用特点

-
位运算的常用场景

-
更复杂的位运算操作

-
- 动态规划(Dynamic Programming)
- 递归+记忆化 -> 递推
- 状态的定义:opt[n], dp[n], fib[n]
- 状态转移方程:opt[n] = best_of(opt[n-1], opt[n-2], …)
- 最优子结构
- DP VS 回溯 VS 贪心
- 回溯(递归)-重复计算
- 贪心-永远局部最优
- DP-记录局部最优子结构/多种记录值
- 并查集
- 并查集(union & find)是一种树形的数据结构,用于处理一些不交集(Disjoint Sets)的合并及查询问题。
- Find:确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。
- Union: 将两个子集并成同一个集合
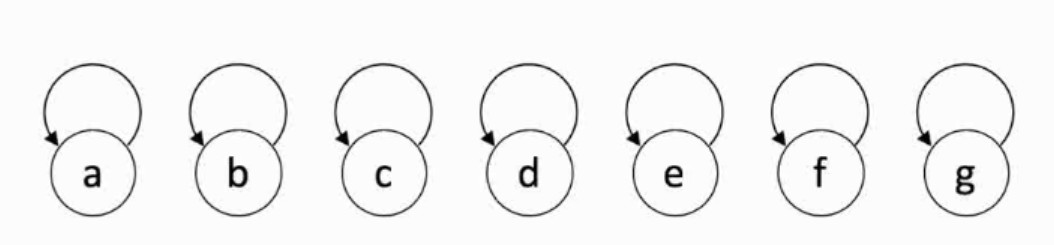
类似现实生活中的帮派识别,组织结构从下往上指向一个老大,老大指向自己。
-
初始状态各自指向自己
-
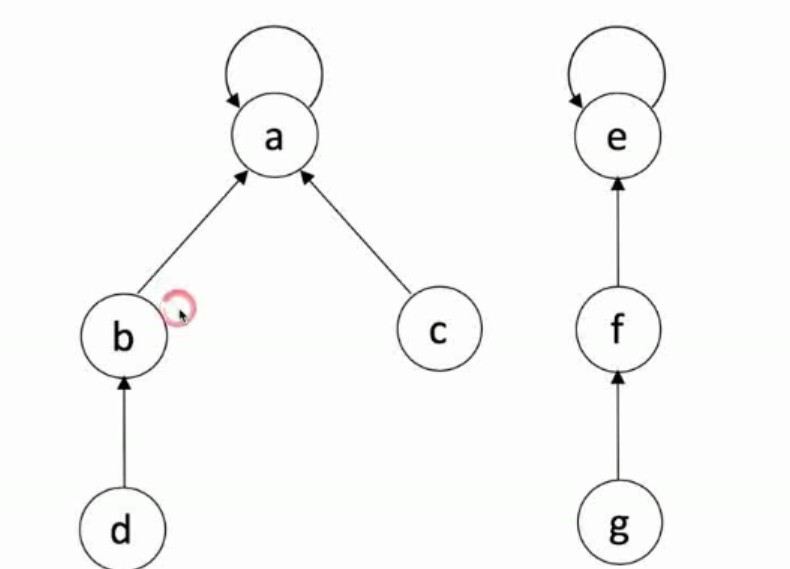
产生合并的关系
-
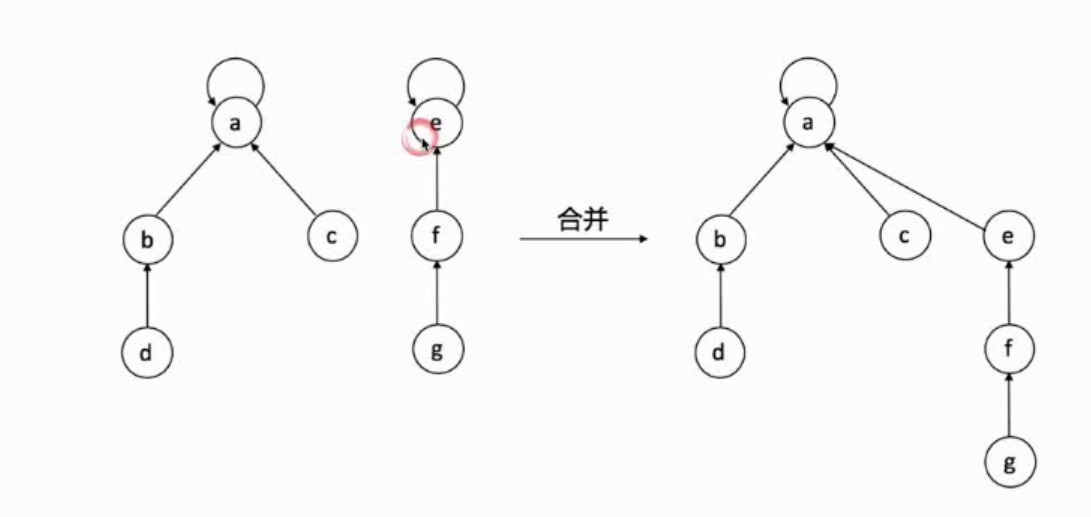
合并
-
示例
-
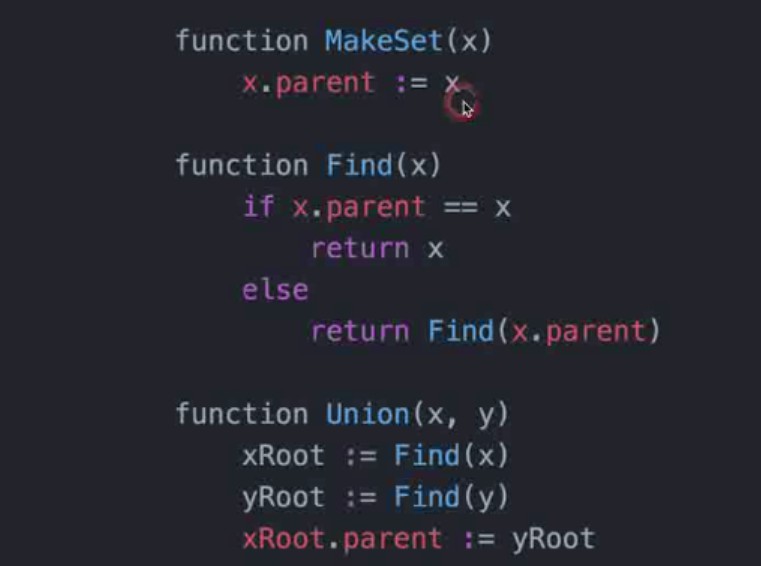
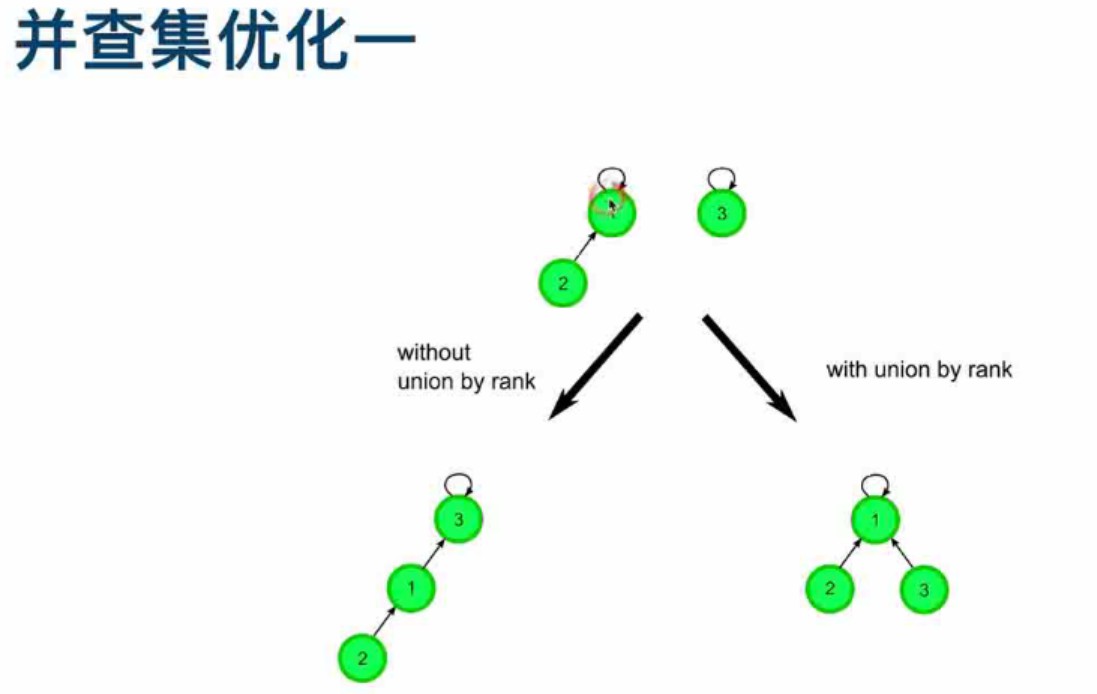
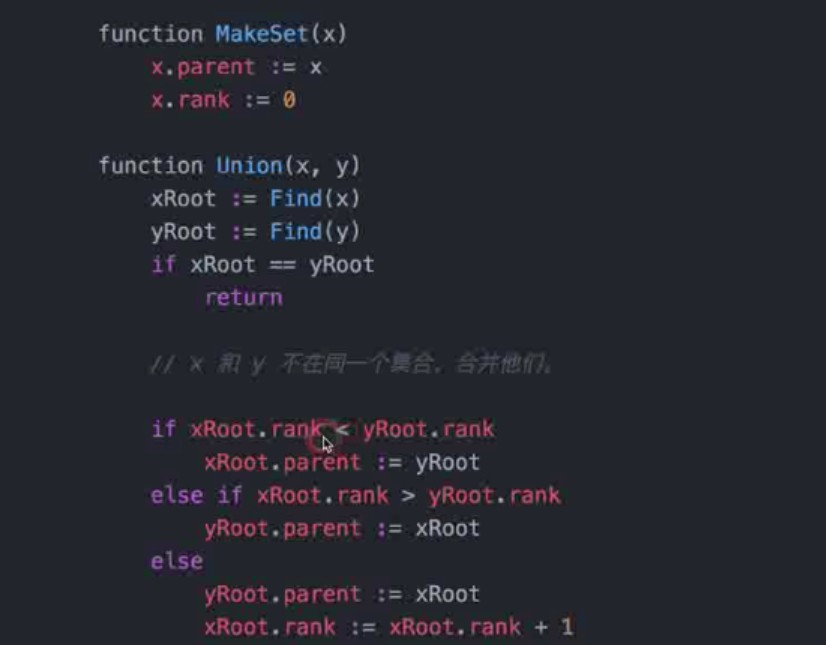
并查集优化:建立rank
-
优化示例
-
并查集优化:路径压缩优于rank
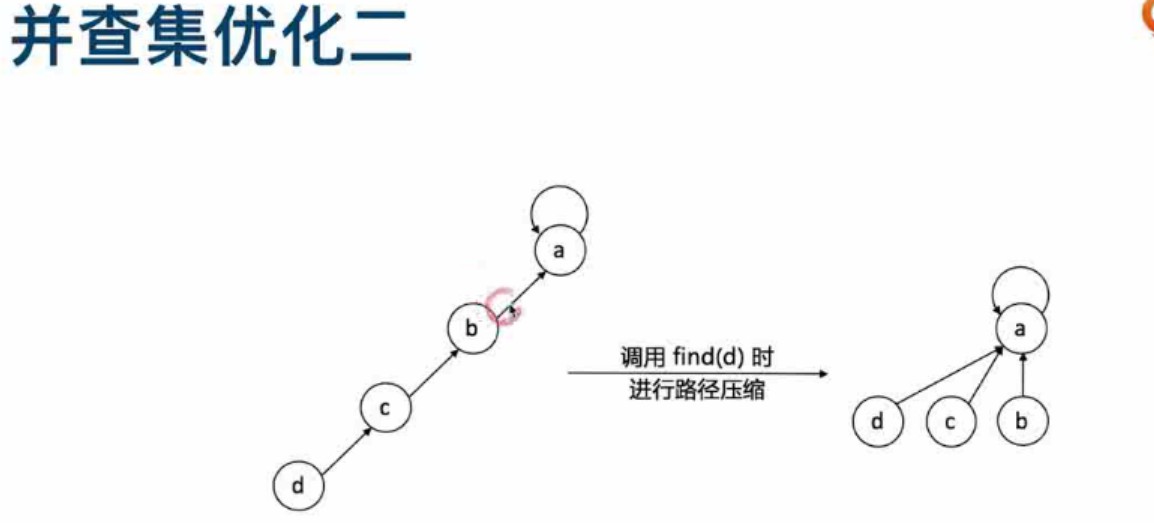
-
LRU Cache(缓存替换算法的一种)
- Least recently used(最近最少使用)
- Double LinkedList(双向链表)
- O(1) 查询
- O(1) 修改、更新
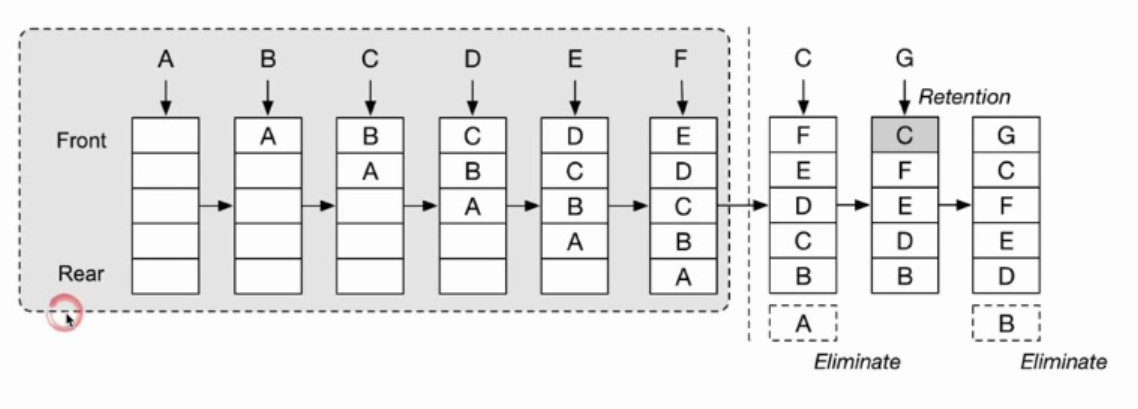
- LFU Cache VS LRU Cache
- LFU - least frequently used(最近最不常用的页面置换法)
- LFU - least frequently used(最近最少使用的页面置换法)
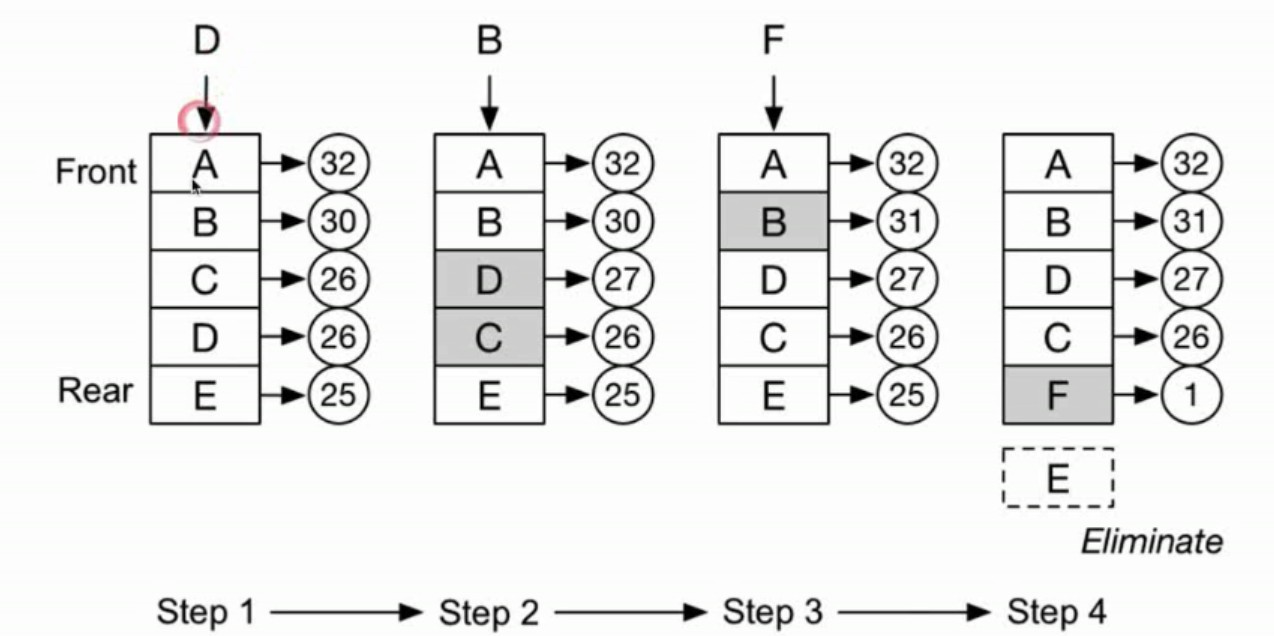
除了介绍的两种外还有很多内存替换算法
- 布隆过滤器(Bloom Filter)
cache和filter是相同的作用,有异曲同工之处。Bloom Filter是通过二进制向量和函数去处理和查找进行过滤,但是存在可能的错误(能确定不存在的部分,但是不能确认一定存在,所以只能作为过滤器)

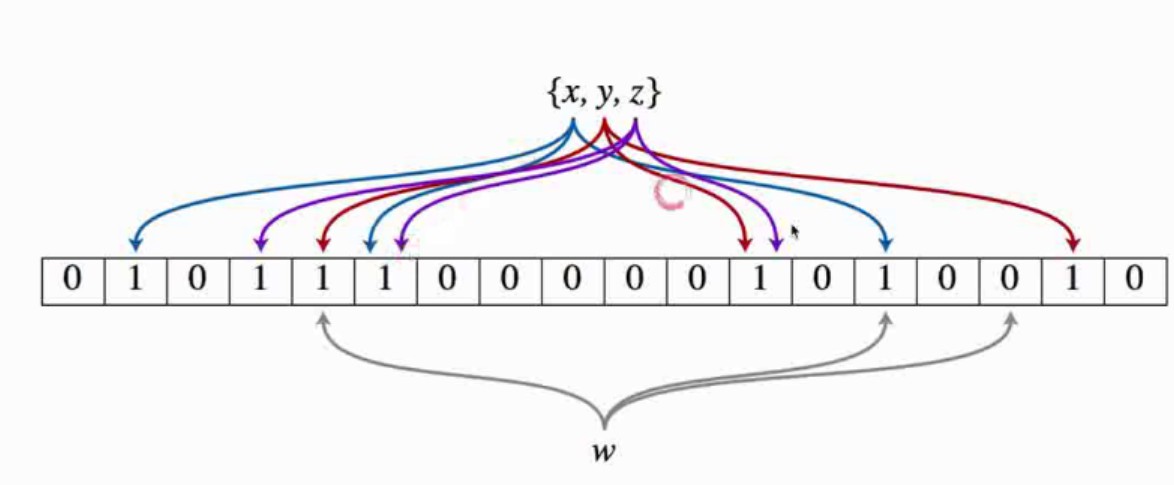
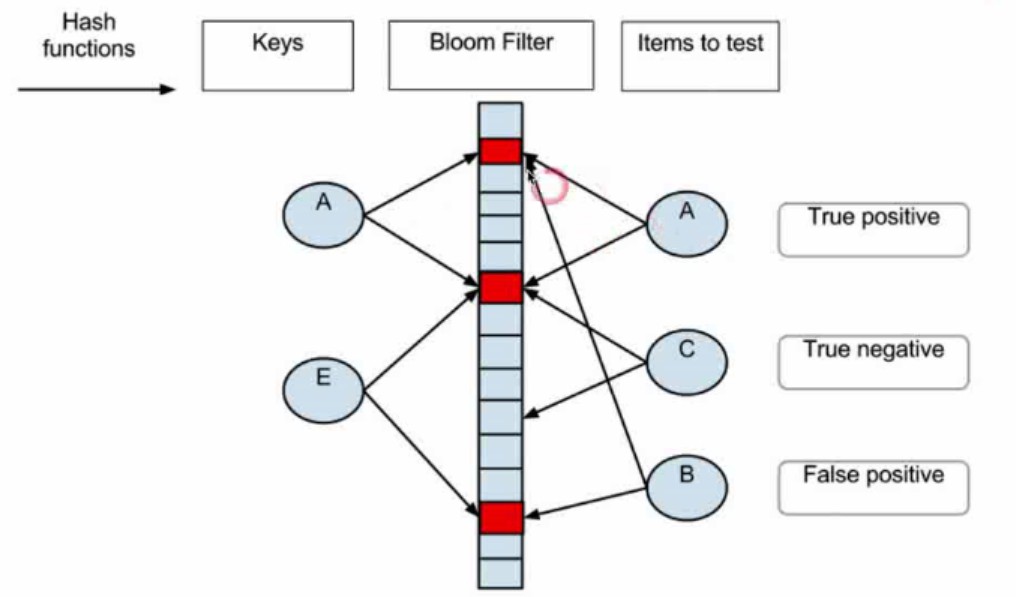
- 五个常用的代码模板
- 递归模板
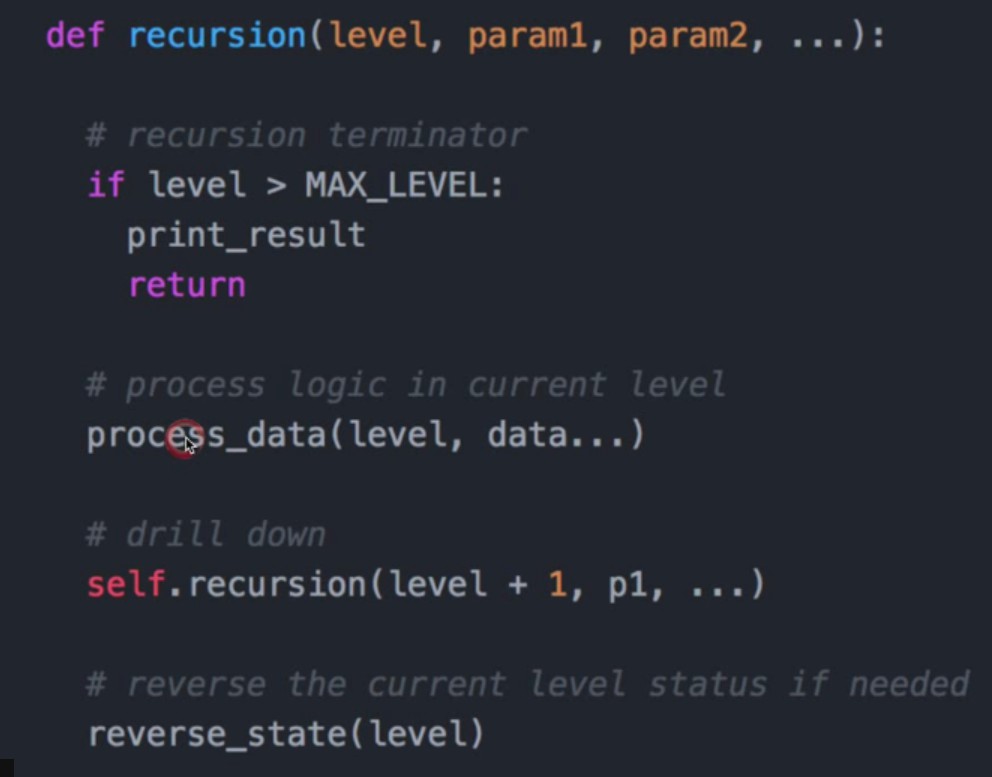
- DFS递归写法
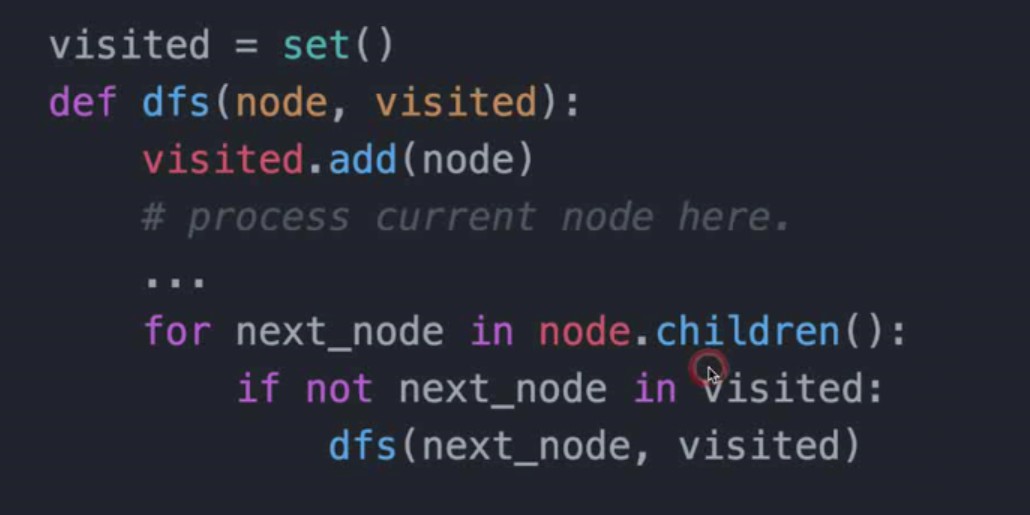
- BFS递归写法
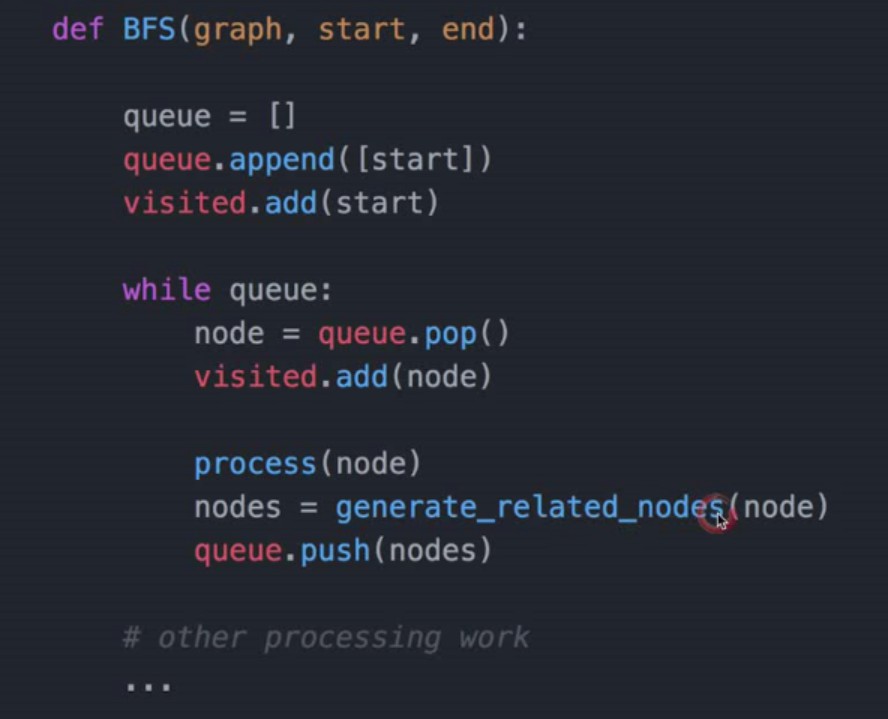
- 二分查找模板

- DP动态规划模板
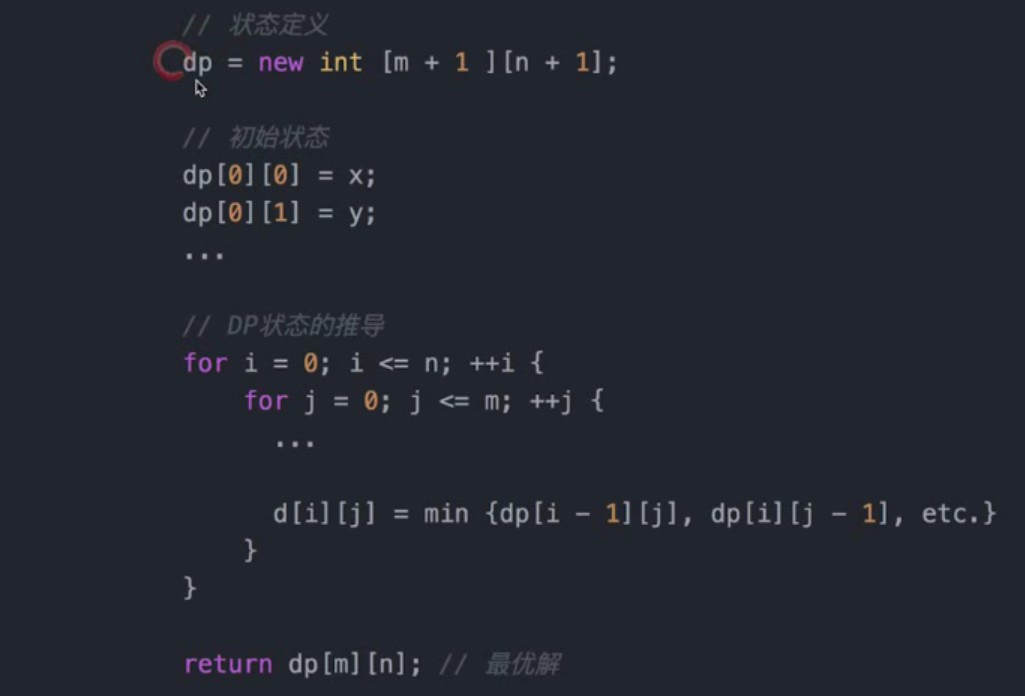
- 递归模板
数据结构与算法是一个长期的过程,需要持续学习和精深学习(可以练习),做过的题目要返回再联系,不要为了切题而切题。
- mac工具集
- keyborad set-up(key Repeat and Delay Until Repeat拉满)
- iTerms + on-my-zsh(env)
- IDE(Pycharm,IntelliJ,GoLand)
- Editors(VS Code,sublime,Atom,VIM)