Redis的背景
2008年,Redis的作者SalvatoreSanfilippo(Antirez)在开发一个叫LLOOGG的网站时,需要实现一个高性能的队列功能,最开始是使用MySQL来实现的,但后来发现无论怎么优化SQL语句都不能使网站的性能提高上去,再加上自己囊中羞涩,于是他决定自己做一个专属于LLOOGG的数据库,这个就是Redis的前身。后来,SalvatoreSanfilippo将Redis1.0的源码开放到GitHub上,可能连他自己都没想到,Redis后来如此受欢迎。
所以其实Redis一开始是为了实现队列而开发,而不是重复造memcached轮子,两者性能并无太大差距,但是memcached只支持存储普通字符串键。
也是因为一开始只是为了解决相对简单场景的队列功能,所以队列功能并不强大。
作者因个人原因已经退出维护者,目前由redis社区维护。
Redis是什么
redis全称是remote dictionary server(远程字典服务器),是一个基于键值对数据结构的高性能非关系型数据库,有如下的特点
性能高: 1. 数据都在内存 2. C语言编写 3. 单线程,非阻塞I/O(使用epoll作为I/O多路复用技术的实现)
代码质量很高: 初版代码只有两万行,十分简洁,是少有的集性能和优雅于一身的开源项目
丰富的功能:
1. 提供键过期功能,可以用来实现缓存
2. 提供了发布订阅,可以实现消息系统
3. 支持Lua脚本功能,可以创造新的Redis命令
4. 提供了简单的事物功能,能在一定程度保证事物特性
5. 提供流水线功能,使客户端能将一批命令一次性传到Redis,减少网络开销
各个数据结构常见指令复杂度和使用场景
Redis常见的数据结构有五种,string, hash, list, set, zset(有序集合)
字符串类型命令时间复杂度:
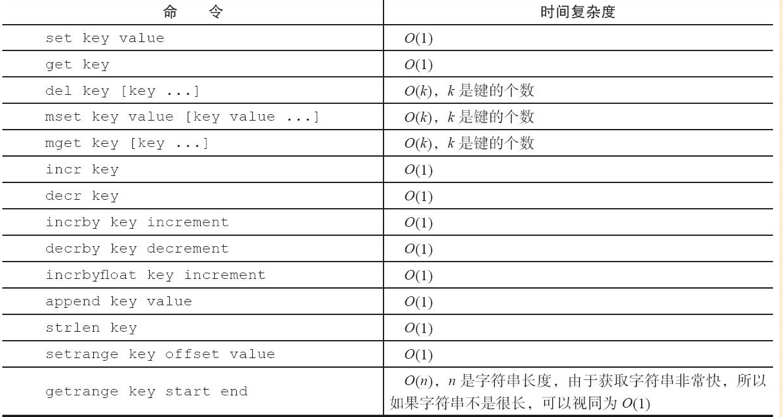
典型使用场景:
1. 共享Session,将session进行集中管理,每次用户更新或者查询登陆信息都直接从Redis集中获取
2. 计数
3. 限速,限制每分钟获取验证码频率,每天获取次数
哈希类型命令的时间复杂度:
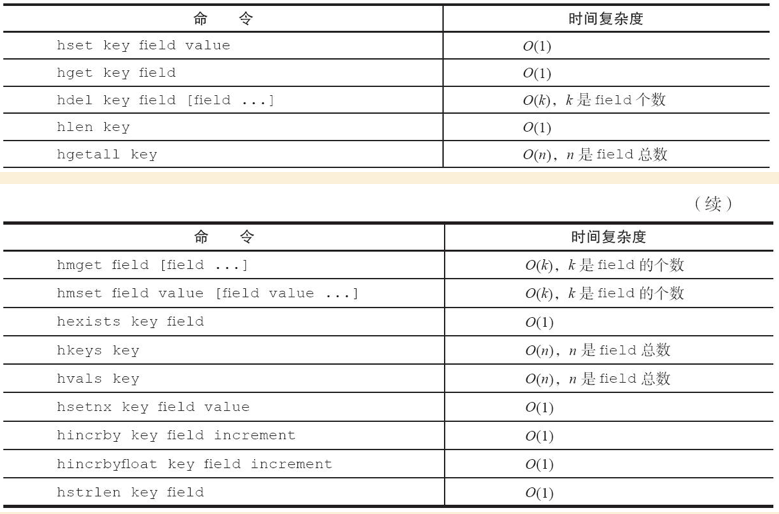
典型使用场景:
1. 缓存用户信息,key为user:id,field为name/age等,相对于使用字符串缓存(key为user:id:name,user:id:age),更节省内存,内聚性好,简单直观
列表类型命令的时间复杂度:
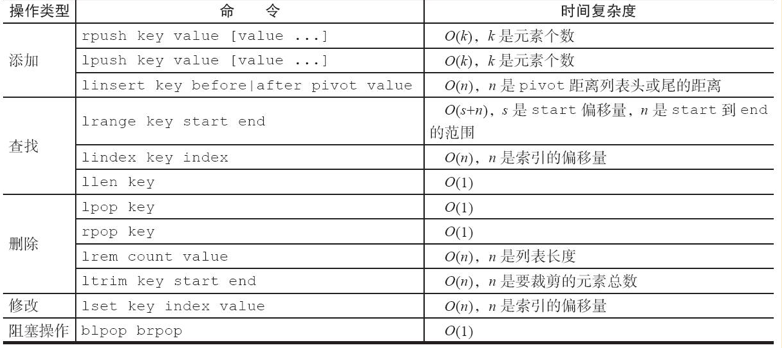
典型使用场景:
1. 消息队列,lpush和brpop组合实现入列出列,brpop阻塞式抢列表尾部的元素
集合类型命令的时间复杂度:
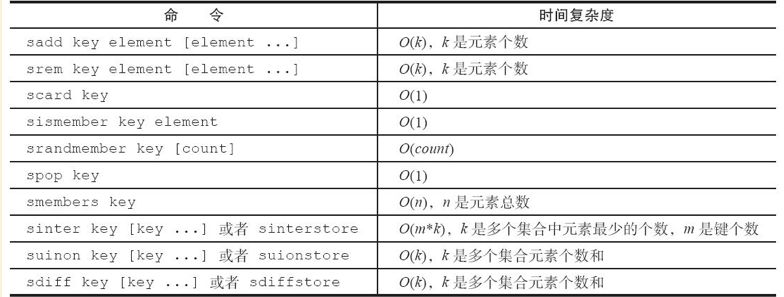
典型使用场景:
和列表不一样: 不允许重复,无序,不能用下标获取元素
1. 标签,例如一个用户对娱乐,体育感兴趣,通过user:id:tags, tag:id:users获取用户感兴趣的标签和喜欢同一个标签的用户
有序集合类型命令的时间复杂度:
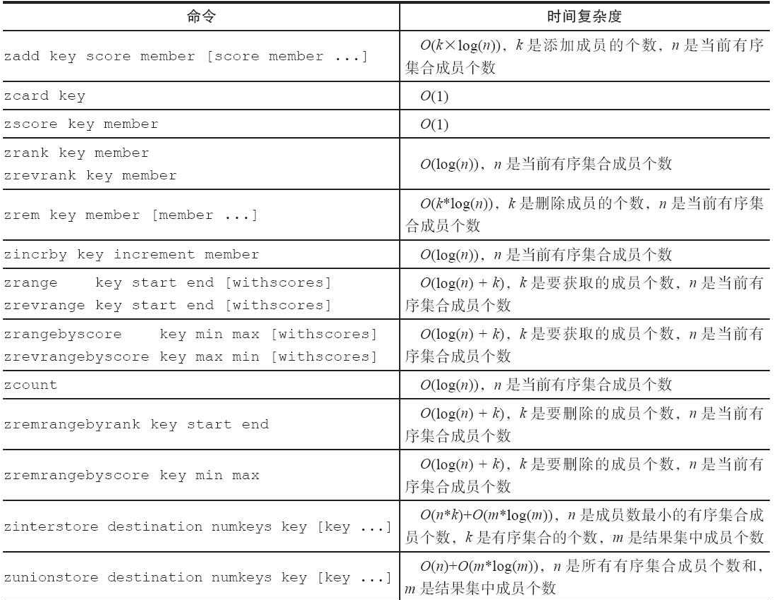
典型使用场景
和集合不一样:可以排序,使用score作为排序依据,提供获取指定分数和元素范围查询
1.排行榜应用
Redis阻塞原因
Redis是典型的单线程架构,所有读写操作都是在一条主线程中完成的。当 Redis用于高并发场景时, 这条线程就变成了它的生命线。 如果出现阻塞, 哪怕是很短时间, 对于我们的应用来说都是噩梦。
可能的阻塞原因:
内因:
1. API或数据结构使用不合理
例如对包含上万元素的hash结构执行hgetall操作,由于数据量比较大且算法复杂度是O(n),执行速度必然很慢,还有keys命令也是同理,一般生产环境是直接禁用keys命令的。
解决方法:把大操作分解为小操作,hgetall改为hmget
2. CPU饱和,并发请求太多或者有大量高复杂度命令执行
3. 持久化阻塞
外因:
1. CPU竞争
进程竞争:
redis是典型的CPU密集型应用,和其他多核CPU密集型服务部署在一起,当其他进程消耗CPU时,将严重影响redis的吞吐量
绑定CPU:
部署Redis时为了充分利用多核CPU,通常一台机器部署多个实例。常见的一种优化是把Redis进程绑定到CPU上,用于降低CPU频繁上下文切换的开销。在父进程创建子进程进行持久化或者复制时,会导致子进程占用CPU而影响父进程,这种情况建议不绑定CPU。
(在多核CPU结构中,每个核心有各自的L1、L2缓存,而L3缓存是共用的。
如果一个进程在核心间来回切换,各个核心的缓存命中率就会受到影响。相反如果进程不管如何调度,都始终可以在一个核心上执行,那么其数据的L1、L2 缓存的命中率可以显著提高。)
2. 内存交换
如果操作系统把redis使用的部分内存换到硬盘,也会导致redis性能急剧下降。
解决办法:保证redis有足够的内存使用,降低系统使用swap的优先级
3. 网络问题
连接拒绝:
超出客户端最大连接数
超出系统进程限制的最大文件打开数,ulimit -n 查询,默认1024,防止too many open files错误
网络延迟:
避免异地机房
理解Redis内存
Redis的内存消耗主要分为三个部分:
1. 对象内存
redis内存占用最大的一块,存储用户数据,可以简单的理解为sizeof(key)+sizeof(values),对于大规模的数据,也要注意key长度的影响,避免使用长键名。
2. 缓存内存
最主要是客户端TCP连接的输入输出缓冲,一般情况下这部分消耗可以忽略,当大量慢连接进来,可能就会导致这部分内存占用变高,还有就是大量数据输出的命令而又无法及时推到客户端,也会导致内存飙升。
3. 内存碎片
频繁更新,大量过期键删除
安全重启,将碎片率高的主节点转为从节点,安全重启
redis的内存回收策略,主要体现在以下两个方面:
1. 删除过期键
出于性能考虑,维护每个键的精准删除j机制会导致消耗大量CPU,对于单线程的redis成本过高,所以redis采用惰性删除和定时任务删除实现回收。
惰性删除:
当客户端读取到带超时属性的键时再执行删除,但是可能一直没访问导致内存泄露,所以提供定时任务作为补充。
定时任务删除:
redis内部维护一个定时任务,默认每秒运行10次,采用自适应算法,根据键的过期比例,使用快慢两种模式回收。
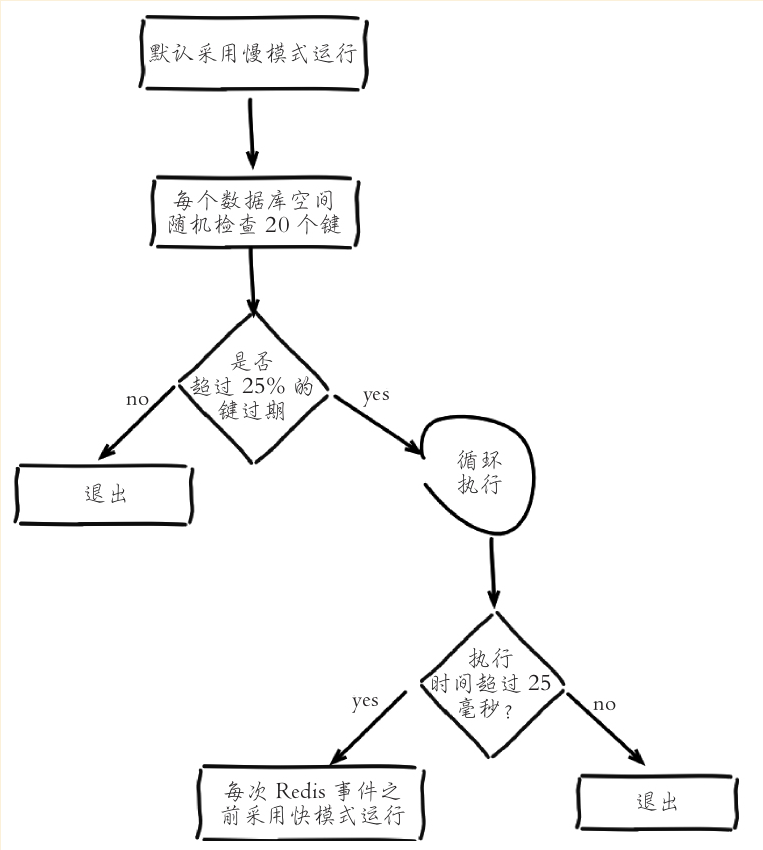
流程说明:
1)定时任务在每个数据库空间随机检查20个键,当发现过期时删除对应的键。
2)如果超过检查数25%的键过期,循环执行回收逻辑直到不足25%或运行超时为止,慢模式下超时时间为25毫秒。
3)如果之前回收键逻辑超时,则在Redis触发内部事件之前再次以快模式运行回收过期键任务,快模式下超时时间为1毫秒且2秒内只能运行1次。
4)快慢两种模式内部删除逻辑相同,只是执行的超时时间不同。
2.内存溢出控制策略
Redis所用内存达到maxmemory上限时会触发相应的溢出控制策略。具体策略受maxmemory-policy参数控制,Redis支持6种策略,如下所示:
1)noeviction:默认策略,不会删除任何数据,拒绝所有写入操作并返回客户端错误信息(error)OOMcommandnotallowedwhenusedmemory,此时Redis只响应读操作。
2)volatile-lru:根据LRU算法删除设置了超时属性(expire)的键,直到腾出足够空间为止。如果没有可删除的键对象,回退到noeviction策略。
3)allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。
4)allkeys-random:随机删除所有键,直到腾出足够空间为止。
5)volatile-random:随机删除过期键,直到腾出足够空间为止。
6)volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有,回退到noeviction策略。
内存优化策略:
1. 缩减键值对象,缩短键名,选择更好序列化工具序列化值,甚至可以加上压缩算法gzip,snappy压缩,但要考虑压缩速度和计算成本。
2. 控制键数量
当使用Redis存储大量数据时,通常会存在大量键,过多的键同样会消耗大量内存。对于存储相同的数据内容利用Redis的数据结构降低外层键的数量,也可以节省大量内存。如图所示,通过在客户端预估键规模,把大量键分组映射到多个hash结构中降低键的数量。
如存在100万个键,可以映射到1000个hash中,每个hash保存1000个元素。
hash的value保存原始值对象,确保不要超过hash-max-ziplist-value限制。
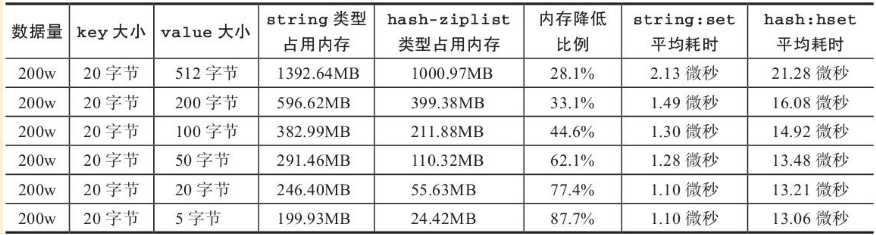
使用hash重构后节省内存量效果非常明显,特别对于存储小对象的场景,内存只有不到原来的1/5。下面分析这种内存优化技巧的关键点:
1)hash类型节省内存的原理是使用ziplist编码,如果使用hashtable编码方式反而会增加内存消耗。
2)ziplist长度需要控制在1000以内,否则由于存取操作时间复杂度在O(n)到O(n2)之间,长列表会导致CPU消耗严重,得不偿失。
3)ziplist适合存储小对象,对于大对象不但内存优化效果不明显还会增加命令操作耗时。
4)需要预估键的规模,从而确定每个hash结构需要存储的元素数量。
5)根据hash长度和元素大小,调整hash-max-ziplist-entries和hash-max-ziplist-value参数,确保hash类型使用ziplist编码。
redis适合做什么不适合做什么
不适合做什么:
从数据规模和数据冷热分析:
数据规模太大的数据不适合用redis,因为数据存放在内存,经济成本太高
冷数据不适合用redis,冷数据放在redis,是一种浪费
适合的使用场景:
1. 缓存
几乎所有大型网站都有使用缓存,可以有效的降低后端数据源的压力
2. 排行榜系统
使用列表和有序集合,可以方便构建各种排行榜系统
3. 计数器应用
视频网站的播放数,电商网站的浏览数,为了保证数据源的实时性,每一次播放和浏览都要加1,并发量大的对传统关系型数据库的性能是一种
挑战,redis天然支持计数功能
4. 社交网络
赞/踩,粉丝,共同好友,推送,下拉刷新
5. 消息队列系统
虽然和专业的消息队列比不够强大,但是对于一般的消息队列功能基本满足